Introduction
Dans un contexte où les données non structurées sont devenues une source riche d’informations utiles à l’entreprise, les solutions de traitements linguistiques vont permettre de générer des données exploitables par les outils analytiques. La plateforme SAP HANA peut répondre à ces besoins importants en mettant à disposition des outils de recherche, d’analyse de texte ainsi que de fouille de texte « Text mining ».
La recherche de texte « String Matching » et « Full Text Search » fonctionne sur des tables de la base de données SAP HANA. Elle permet de sélectionner les chaines de caractères dans différents textes.
L’analyse de texte dispose de plusieurs méthodes telles que la « tokanisation » c’est-à-dire une séparation de tous les mots d’un texte, la « lemmatisation » basée sur la forme canonique des mots, la « stemmatisation » basée sur la racine des mots ou des méthodes d’analyse sémantique plus poussées.
La fouille de texte détermine la sémantique des mots et textes et permet le classement des textes et documents.
La recherche de texte
Grace aux services dédiés « SAP HANA Information Access Services » il est possible d’exploiter les données non structurées et d’en extraire des informations précises. Par exemple extraire les avis de consommateurs concernant un produit depuis un blog ou identifier des problématiques récurrentes dans les memos des centres de supports.
SAP Hana propose également des scripts Python, des interfaces HTML5 pour aider à construire ces traitements de recherche.
Les services « Information Access Services » s’appuient sur le moteur de recherche et le text processor.
SAP HANA met également à disposition le SAP HANA Info Access Toolkit for html 5 afin de pouvoir développer des applications de recherche.
La boîte à outils fournit des éléments d’interface utilisateur (widgets) tels qu’une zone de recherche et de filtre, une liste de résultats avec une vue détaillée et des graphiques pour des analyses de base sur l’ensemble de résultats. Les widgets sont interconnectés et s’adaptent en temps réel aux entrées utilisateur.
La boite à outils propose des bibliothèques HTML5 et javascript : JQuery / JQueryUI, d3 (Data Driven Documents) et Tempo. Les widgets utilisent le service HTTP d’accès aux informations SAP HANA. Un navigateur web suffit pour utiliser l’interface.
Ces outils utilisent l’API SAP HANA Simple Information Access (SinA) et un modèle virtuel (Attribute View) pour exécuter les recherches. Il est également possible d’utiliser des CDS Views (Modèles Core Data Service) via ODATA pour afficher les résultats d’une recherche dans l’interface Fiori.
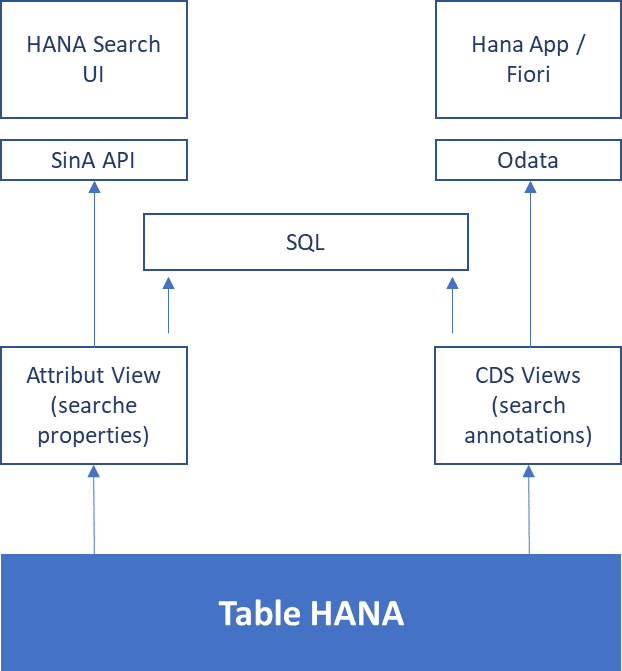
Pour mettre en place un modèle de recherche il va falloir créer un full text index afin de pouvoir exécuter des recherches floues (fuzzy search) ou recherches exactes.
La recherche floue fonctionne sur les types de données suivants :
- TEXT
- SHORTTEXT
- BINTEXT
- CLOB
- NLOB
- BLOB
- NVARCHAR
- VARCHAR
- DATE
La création de l’index de recherche doit être fait en même temps que la création de la table pour les types TEXT, BINTEXT, SHORTEXT.
Pour les autres, il doit être fait après la création de la table.
Exemple 1
CREATE COLUMN TABLE MyTableName (
ID INTEGER PRIMARY KEY,
TITRE NVARCHAR(150),
TEXTE CLOB
) ;
CREATE FULLTEXT INDEX MyIndexName ON MyTableName(TEXT)
FUZZY SEARCH INDEX ON ;
Exemple 2
CREATE COLUMN TABLE « MyTableName » (
ID INTEGER PRIMARY KEY,
TITRE NVARCHAR(150),
TEXTE SHORTTEXT(5000) FUZZY SEARCH INDEX ON
);
Dans ce deuxième exemple, la création du full text index est implicite.
Il est possible de contrôler l’état de l’index après insertion des données dans la table :
SELECT INDEXING_STATUS(« TEXTE »),
INDEXING_ERROR_CODE(« TEXTE »),
INDEXING_ERROR_MESSAGE(« TEXTE »)
FROM MyTableName;
La recherche d’une information utilise la fonction CONTAINS de cette façon :
Recherche exacte du mot 'economy'
SELECT « ID », » TITRE », « TEXTE » from MyTableName WHERE CONTAINS(« TEXTE », ‘economy’) ;
Seuls les articles contenant le mot ‘economy’ seront retournés.
Recherche floue à partir de la chaine de caractère 'economi'
SELECT * from MyTableName WHERE CONTAINS(« TEXTE », ‘economi’, FUZZY (0.2)) ;
Ici, tous les articles contenant une chaine de caractère se rapprochant de ‘economi’ seront retournés. L’indice de précision de la recherche est indiqué dans la fonction CONTAINS : FUZZY (0.2). Le score est visible avec l’utilisation de la fonction Score() : select score() as score, ID, TITRE from….
Ex avec un indice supérieur à 0.2
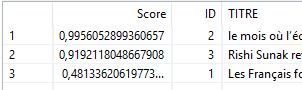
Trois articles sont retournés et contiennent un ou plusieurs mots proches de ‘economi‘
Ex avec un indice supérieur à 0.7
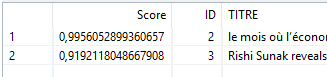
Deux articles sont retournés et contiennent un ou plusieurs mots proches de ‘economi’
Analyse de texte
L’analyse de texte permet de donner une structure au contenu textuel non structuré, d’exposer le balisage linguistique pour les explorations de texte, de classer les entités (personnalités, entreprises…), et d’indiquer les faits du domaine (sentiment, sujet, besoins…). Dans SAP HANA, l’analyse de texte prend en charge jusqu’à 11 langues.
Grace à de telles fonctions, il est donc possible de mettre en place une structure d’analyse afin d’identifier des tendances, des comportements, des avis ou, d’un point de vue opérationnel, d’être alerté et d’anticiper sur des problématiques concernant l’entreprise (panne récurrente sur certains lots d’appareils). Tout cela peut être réalisé en temps réel sur la plateforme SAP HANA.
Bien sûr il est nécessaire de paramétrer un certain nombre d’éléments pour pouvoir réaliser des analyses. Tout d’abord, mettre en place un flux pour capter l’information, ensuite filtrer les documents, articles, mails…, définir des tables pour y charger les données récupérées, définir les index de recherche et d’analyse et ensuite construire un modèle d’analyse.
SAP HANA dispose d’outil permettant de capter des flux d’information. Le Data Provisioning Agent intègre des connecteurs ou « adapters » vers des réseaux sociaux par exemple. Lors de la création d’un « agent », HANA crée automatiquement une fonction virtuelle qui peut être requêtée. Mais dans ce cas, les données ne sont pas persistantes. Si l’on veut capter des informations pour les intégrer dans des tables, il est aussi possible d’utiliser, en complément du Data Provisioning Agent, le Smart Data Integration Flowgraph qui permet de filtrer les flux et ne capter que les articles pertinents pour les intégrer dans une table.
Pour pouvoir réaliser une analyse de texte dans une table, il va être nécessaire de créer la table et un FullText Index de la façon suivante :
CREATE COLUMN TABLE RECHERCHE_TEXTE » (
DOCUMENT_ID INTEGER PRIMARY KEY,
TITRE_DOCUMENT NVARCHAR(150),
CONTENU_DOCUMENT NVARCHAR(2000) );
CREATE FULLTEXT INDEX SEARCHINDX ON « RECHERCHE_TEXTE »(« CONTENU_DOCUMENT »)
LANGUAGE DETECTION (‘EN’,’FR’)
TEXT ANALYSIS ON
CONFIGURATION ‘LINGANALYSIS_FULL’ ;
Lors de la création de l’index, une table est créée : $TA_SEARCHINDX
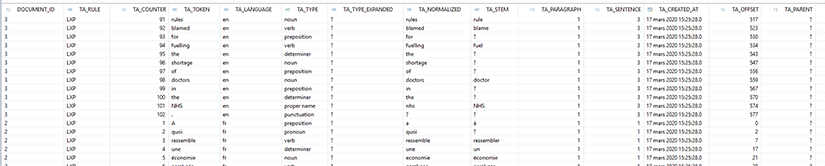
Cette table contient la liste de tous les mots des documents, la langue qui a été détectée, le type de mot.
L’analyse de texte SAP HANA applique des techniques linguistiques et statistiques complètes pour extraire et classer le texte non structuré en entités et domaines.
La dernière ligne du script de création de l’index indique la méthode par laquelle l’index va être créé. Voici les différentes méthodes :
- LINGANALYSIS_BASIC : Analyses linguistiques basiques : une tokenisation est effectuée mais pas de normalisation ni de stemming.
- LINGANALYSIS_STEMS : Normalise et effectue un stemming sur les token.
- LINGANALYSIS_FULL : Effectue une analyse linguistique complète (voir exemple ci-dessus)
- EXTRACTION_CORE : Extrait les entités basiques du texte, en incluant les personnes, les lieux, les entreprises…
- EXTRACTION_CORE_VOICEOFCUSTOMER : Extrait des entités supplémentaires pour prendre en compte les « sentiments » et les attentes. Il permet d’identifier les sentiments positifs et négatifs ou une opinion à propos d’un sujet.
- EXTRACTION_CORE_ENTERPRISE : Extraction de données d’entreprise comme les fusions, les changements d’organisation ou les sorties de produits. Se focalise sur le métier.
- EXTRACTION_CORE_PUBLIC_SECTOR : Extrait les données sensibles liées aux personnalités publiques, évènements ou organisations.
Il est donc possible maintenant, à partir de cette table, d’analyser les articles qui ont été récupérés dans des documents ou streams.
Analyse de texte
La fonctionnalité de fouille de texte se base sur l’analyse du texte contenu dans des documents pour les comparer et les classer.
L’exploration de texte prend en charge des fonctions permettant de déterminer les documents et termes associés et pertinents les mieux classés par rapport à un ensemble de documents de référence donné et d’effectuer une analyse statistique. Il prend également en charge les méthodes de catégorisation (classification) des documents, étant donné un ensemble de documents de référence avec des catégorisations prédéfinies.
L’exploration de texte fonctionne au niveau du document. Elle détermine la sémantique sur le contenu global des documents par rapport aux autres documents. Cela diffère de l’analyse de texte, qui effectue une analyse linguistique et extrait les informations intégrées dans chaque document. Elles sont complémentaires.
L’exploration de texte peut être utilisée pour analyser les données à volonté dans diverses tables de la base de données sélectionnées après leur saisie. Mais la principale utilisation envisagée est la catégorisation de document dans un flux, par ex. articles de presse ou incidents de support client. Les autres fonctions et les résultats statistiques seront également nécessaires pour une analyse plus approfondie afin d’ajuster la précision et de maintenir l’ensemble des documents de référence.
D’autres cas d’utilisation peuvent être des applications de recherche qui permettent de retrouver des documents et des termes connexes ou de suggérer des termes de recherche basés sur une sous-chaîne initiale.
L’exploration de texte compare les documents à l’aide d’un modèle de valorisation.
Cela signifie que seul le nombre d’occurrences de termes est pris en compte, pas l’ordre dans lequel ils apparaissent. La nature du contenu d’un document est définie par les fréquences relatives (décomptes) des termes qu’il utilise.
Un terme est plus qu’un simple mot. L’exploration de texte bénéficie de l’analyse de texte pour étendre la définition de ce qu’est un terme. Le prétraitement d’analyse de texte permet aux termes d’être basés sur les racines normalisées des tokens, couplés à leurs parties de discours. Les entités et expressions contenant plusieurs mots sont également utilisées comme termes.
Un document n’est pas évalué par lui-même de manière autonome. Il est comparé à d’autres documents dans un ensemble de référence donné.
L’ensemble de documents de référence est généralement une table entière, mais il peut également être une partie sélectionnée d’une table. Le document d’entrée peut lui-même être l’un des documents de référence ou non, et il peut être distinct de la table.
SAP HANA fourni une interface JavaScript pour le moteur de fouille de texte. On peut notamment utiliser des fonctions telles que getRelatedTerms ou getRelatedDocuments. Des fonctions utilisables dans les requêtes SQL sont également disponibles.
- TM_GET_RELATED_TERMS : Les termes les plus présents dans texte et en relation avec un terme spécifique.
- TM_GET_RELEVANT_TERMS : Les termes les plus présents et les plus pertinents décrivant un document.
- TM_GET_SUGGESTED_TERMS : Les termes les plus présents qui matchent avec un terme spécifique.
- TM_GET_RELATED_DOCUMENTS : Les documents les plus présents en relation avec un document spécifique.
- TM_GET_RELEVANT_DOCUMENTS : Les documents les plus présents pertinents par rapport à un terme spécifique.
- TM_CATEGORIZE_KNN : Classification d’un document en fonction d’une taxonomie en utilisant la méthode KNN (k nearest neighbor).
La syntaxe pour créer un fulltext index dans le cas de Text Mining diffère légèrement de celle du Text Analysis :
CREATE FULLTEXT INDEX SEARCHINDX ON « RECHERCHE_TEXTE »(« CONTENU_DOCUMENT »)
FAST PREPROCESS OFF
SEARCH ONLY OFF
TEXT MINING ON
CONFIGURATION ‘LINGANALYSIS_FULL’;
Après la création de l’index, 3 nouvelles tables sont créées :
$TM_DOCUMENTS_SEARCHINDX
$TM_MATRIX_SEARCHINDX
$TM_TERMS_SEARCHINDX
Ces tables permettront l’utilisation des fonctions de classification ou de recherche de documents en relation avec un document particulier ou un terme. Ce modèle de tables pourra donc être utilisé par des ‘function table’ si l’on veut utiliser les fonctions SQL mises à disposition par HANA ou directement par des calculation views.
CONCLUSION DE L’EXPERT
Dans un monde qui nécessite de la réactivité par rapport à un marché ou des problématiques, et lorsqu’il est nécessaire de gagner en productivité, l’analyse d’éléments non structurés par les outils de la plateforme temps réel SAP HANA apporte tous les moyens nécessaires pour capter les intentions ou les sujets à traiter en priorité. De nos jours ce type d’information « Non Structuré » est de plus en plus présente dans les entreprises (Réseaux sociaux, Objets connectés, Stream d’information, …)
Il devient alors très intéressant de pouvoir construire un modèle analytique à partir d’articles de réseaux sociaux ou de tickets de centre de support. La plateforme SAP HANA n’est pas seulement une base de données « In Memory », c’est aussi une plateforme applicative qui intègre également des outils de Machine Learning (EML). Coupler l’analyse de document avec le « machine learning » est donc possible sur cette plateforme.
Avec la plateforme SAP HANA et ces outils, vous pourrez facilement traiter des documents ou des fils d’informations afin d’améliorer l’efficacité et la pertinence des analyses de vos client ou de vos utilisateurs finaux.



