Introduction
SAP HANA (acronyme de High performance ANalytic Applicance) est une Appliance, une combinaison hardware et software, optimisée pour tirer parti des technologies les plus récentes en matière de processeurs multi-cœurs et de mémoire vive.
Grâce à cela, il est possible de gérer et analyser des données de types variés à très grande échelle et en temps réel. SAP HANA a été développé autour des technologies « In-memory » et du stockage en colonne.
Le terme « in-memory » désigne le principe selon lequel les données ne sont plus stockées sur disque mais dans la RAM dans un format compressé non relationnel. Cette technologie permet d’atteindre des vitesses de lecture et d’écriture beaucoup plus importantes qu’avec des systèmes de base de données classiques.
L’objectif de la technologie HANA est de rapprocher les entrées/sorties le plus près possible du processeur en limitant les accès disque pour réduire les temps de calcul.
Dans cet article, nous vous expliquerons le concept de base de données en colonnes, l’intérêt du « In-Memory » ainsi que le fonctionnement général de la plateforme SAP HANA.
SAP HANA : Le concept de base de données en colonne
Nous connaissons tous le concept des bases de données relationnelles, qui sont optimisées pour le stockage de ligne de données. Ce concept est le plus couramment utilisé.
Il est important de saisir la différence entre le stockage des données en ligne et en colonne afin d’optimiser les traitements. Prenons l’exemple ci-dessous, illustrant une base de données relationnelle classique :
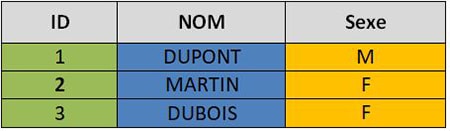
En mémoire, les données sont organisées différemment si le stockage s’effectue en ligne ou en colonne.
Stockage en lignes

Stockage en colonnes

Le stockage des données en colonne permet un traitement des opérations plus rapides et permet l’accès séquentiel en mémoire. La compression est également facilitée puisque, par exemple, {M, F, F} peut être écrit {M, 2F}.
Sommairement :
| Stockage en lignes | Stockage en colonnes |
|
|
Notre avis : Le stockage en ligne est donc à préférer lorsque toutes les colonnes d’une table sont utilisées dans un rapport et qu’il y a peu d’enregistrements, et le stockage en colonne est à utiliser en cas d’un grand volume de lignes à agréger et analyser.
Bien que le stockage des tables en colonne soit optimisé pour la lecture, le coût en écriture est relativement élevé puisque le tri doit être régénéré à chaque mise à jour.
SAP HANA : Pourquoi « In-memory » ?
SAP HANA permet de monter en mémoire les données et permet de répondre instantanément à des besoins analytiques. Cette augmentation de vitesse s’explique par le fait que les tâches en mémoire s’exécutent en nanosecondes (contrairement aux systèmes physiques où les tâches s’exécutent en millisecondes).
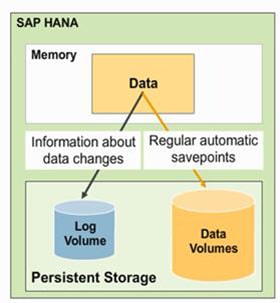
La partie Data « In-Memory » contient seulement les données montées en mémoire, le persistent Storage contient lui toutes vos données, elles sont stockées comme suit :
- Le volume du journal (Log Volume) contient les informations sur les modifications de données (insert, update, delete) et est directement enregistré à chaque commit.
- Le volume de données (Data Volume) contient quant à lui les données et informations ainsi que les données de modélisation. Des points de sauvegarde automatiques sont exécutés entre la mémoire et le stockage.
SAP a développé un système de mémoire dédié pour l’écriture et la lecture des données. Ce principe est appelé « Insert Only on Delta ».
Ce système repose sur une mémoire « divisée ». Une mémoire principale optimisée pour la lecture et où les données sont stockées en colonnes triées et des mémoires delta pour lesquelles l’écriture est optimisée et où les données ne sont pas triées.
Avantages de SAP HANA In Memory
- La base de données HANA tire parti du traitement en mémoire pour offrir des vitesses de récupération de données les plus rapides possibles, ce qui est attrayant pour les entreprises qui ont des transactions en ligne à grande échelle.
- Le stockage en colonne permet de compresser les données jusqu’à 10 fois, réduisant ainsi l’espace de stockage des données.
Notre avis : Le stockage des données « In-memory » de SAP HANA constitue une avancée majeure pour l’analyse. Il permet de réduire considérablement les temps d’accès à la donnée.
Description de la plateforme SAP HANA
SAP HANA n’est pas qu’une base de données in-memory mais une Appliance mettant à disposition des services de développement d’applications ainsi que des systèmes de traitement et d’intégration de données :
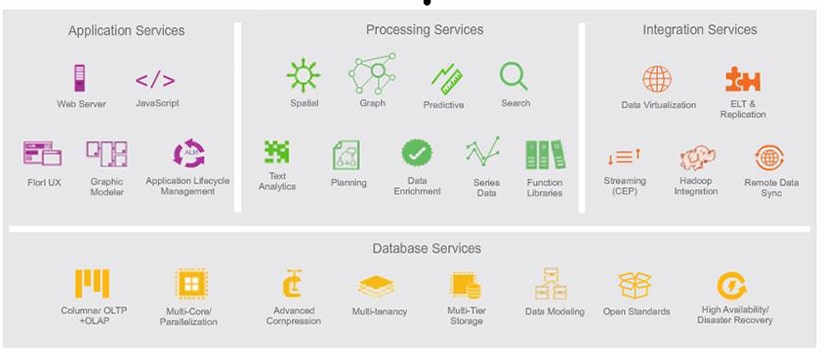
Les services « Application XS » (Application Services) regroupent un ensemble de fonctionnalités telles qu’un serveur web embarqué, le support du JavaScript, des interfaces et librairies Fiori ainsi qu’une application de « Lifecycle management ».
Côté traitement des données (Processing Services), SAP HANA embarque des fonctionnalités de traitement de données spatiales, de graph, de prédiction, de recherche, d’analyse, de fouille de texte, de planification et de consolidation. Il est aussi possible de développer ses propres fonctions de traitement grâce à un ensemble de librairies « Application Function Librairies » (AFL).
Parmi cet ensemble, deux librairies sont à retenir, la Predictive Analysis Library (PAL) pour le développement de modèles prédictifs et la Business Function Library (BFL) pour la création de fonctions métiers complexes.
En ce qui concerne l’intégration des données (Integration Services), HANA dispose de systèmes de virtualisation et de plusieurs services de réplication et de streaming de données. La plateforme supporte également la synchronisation des données à distance et peut s’interfacer avec un système Hadoop.
Les services de base de données (Database Services) quant à eux prennent en charge aussi bien l’ « Online Analytic Processing (OLAP) » que le l’ « Online Transaction Processing (OLTP) » et supportent l’exploitation des processeurs multi-cœurs et la parallélisation des traitements.
Notre avis : SAP HANA est plus qu’une base de données, c’est une véritable plateforme de développement qui permet de faire plus que du stockage de données. Les applications et fonctions de la plateforme HANA sont toutes optimisées pour travailler avec les données « In-memory »
Cas d’utilisation du système HANA
Le système HANA peut être utilisé dans plusieurs scenarios différents :
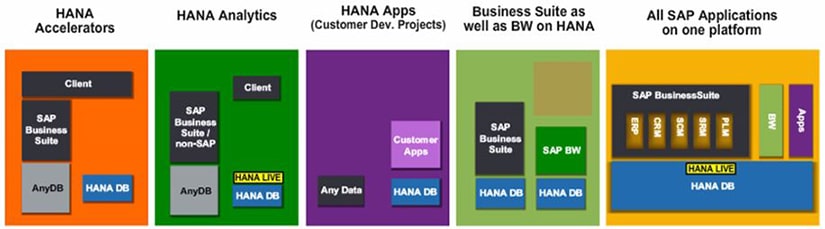
Side-Car – SAP HANA Accelerators
SAP HANA peut être utilisée comme une base de données secondaire, les données y sont répliquées en temps réel depuis une source SAP ou non SAP afin de bénéficier de ses performances. Plusieurs options de réplication sont disponibles, elles seront abordées plus tard dans ce document.
Après la réplication des données vers HANA, il est possible de créer des modèles d’informations, ou « vues » qui seront consommés par les outils de reporting. Il est également possible d’utiliser les « HANA Live » dans une configuration « HANA Analytics ». Les HANA live sont des vues prédéfinies adaptées au modèle de données de son ERP ECC.
Nouvelles applications – SAP HANA Apps
Grâce aux librairies HANA et à son interface de développement « Web-based Development Workbench », les développeurs peuvent créer de nouvelles applications basées sur HANA et exploitant les vues de calcul ou d’analyse.
Base de données principale – ECC/BW on HANA
HANA joue le rôle de base de données principale, tous les services liés sont fournis par SAP HANA, on peut notamment citer des configurations comme SoH (SAP Business Suite on HANA) ou BW on HANA, à ne pas confondre avec S4/HANA et BW4/HANA, des outils spécialement conçus pour HANA.
Plate-Forme intégrée
Il s’agit d’une configuration dans laquelle toutes les applications SAP sont sur la même plateforme HANA. On peut notamment citer la nouvelle « Business Suite » de SAP, S4/HANA, créée nativement sur SAP HANA et intégrant les nouvelles interfaces Fiori. Dans cette configuration, tout est géré dans le système HANA. La couche applicative, la « Business Suite », a été spécialement pensée pour ce système.

Parmi les caractéristiques notables de S/4HANA, nous pouvons citer :
- Un débit de donnée plus important et un encombrement total diminué
- Des analyses et du reporting SAP plus rapides
- Simplification des processus
- SAP ERP, CRM, SRM, SCM et PLM déployés en parallèle
- Interfaces SAP FIORI UX disponibles pour mobile, tablette et ordinateur
- Extensions édition Cloud disponibles
SAP Cloud accéléré par SAP HANA
Solution de cloud public ou privé, le Cloud accéléré par SAP HANA permet à des applications comme SuccessFactors ou Ariba de bénéficier de la puissance de la base de données in-memory. Le SAP HANA Cloud Platform, permet d’accéder aux services d’infrastructure de base de données ou d’application de HANA en mode SaaS ou PaaS. Deux offres principales sont disponibles, SAP HANA Enterprise cloud, offre Cloud entièrement gérée par SAP et le SAP HANA One, hébergement complet et public de la plateforme HANA.
Notre avis : On constate que la plateforme SAP HANA peut être utilisée dans des cas très différents, de la donnée opérationnelle à la donnée décisionnelle.
Nous avons d’ailleurs développé en interne chez DeciVision, sur cette plateforme SAP HANA, les HANA Rapid Views, qui sont des datamarts virtuels temps-réel, permettant d’accélérer vos déploiements BI sur les données SAP FI-CO, SD, MM, …



