Introduction
L’arrivée du cloud constitue une nouvelle ère : nombreuses sont les entreprises se laissant séduire par ses atouts indéniables en termes d’accessibilité, de maintenance et de flexibilité.
C’est notamment le cas pour Data Factory qui, avec sa plateforme Azure affirme sa transition vers le cloud.
Azure Data Factory est un ETL / ELT managé dans le cloud disponible sur Microsoft Azure, à la popularité grandissante. Il vise à remplacer progressivement SQL Server Integration Service (SSIS), l’ETL plus ancien et traditionnellement On-premise de Microsoft. Les deux ne sont cependant pas antagoniques car il est possible d’exécuter des packages SSIS dans ADF, peut être comme une première étape pour un lift-and-shift.
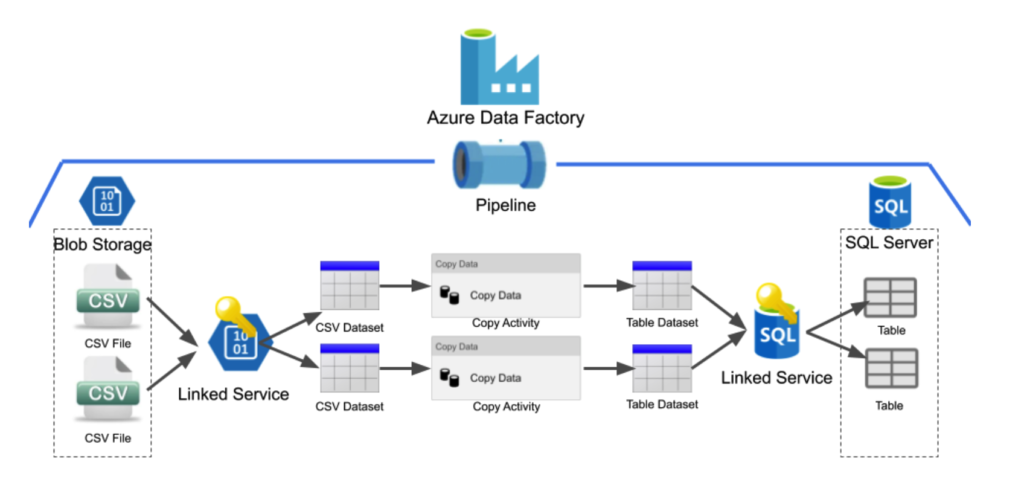
L’architecture de Data Factory
Sous le capot, c’est soit un ensemble de machines gérées par Azure (pour les pipelines), soit un cluster Spark (pour les Data Flows) qui s’occupe de l’exécution. ADF n’est donc pas fondamentalement limité en matière de volumétrie.
Edition
ADF garde une interface visuelle cohérente, qui sera familière à ceux qui ont l’habitude d’utiliser des outils ETL comme Talend.
C’est cette interface que vous utiliserez pour la construction de vos pipelines.
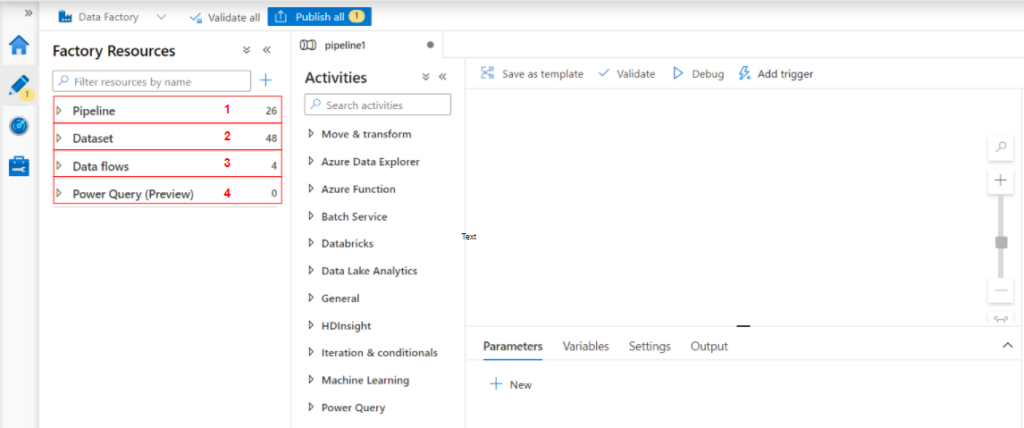
Pipeline
Une fabrique de données peut avoir un ou plusieurs pipelines.
Les pipelines créés sont visibles à gauche de l’interface (1), les modules à inclure dans le pipeline sont sous la rubrique activités (2).
Un pipeline constitue un regroupement logique d’activités qui exécutent ensemble une tâche. Par exemple, un pipeline peut contenir un ensemble d’activités (3) qui ingèrent et nettoient des données de journal, puis lancent un flux de données de mappage pour analyser les données de journal. Le pipeline vous permet de gérer les activités en tant que groupe et non pas individuellement. Vous pouvez déployer et planifier le pipeline, plutôt que chaque activité séparément.
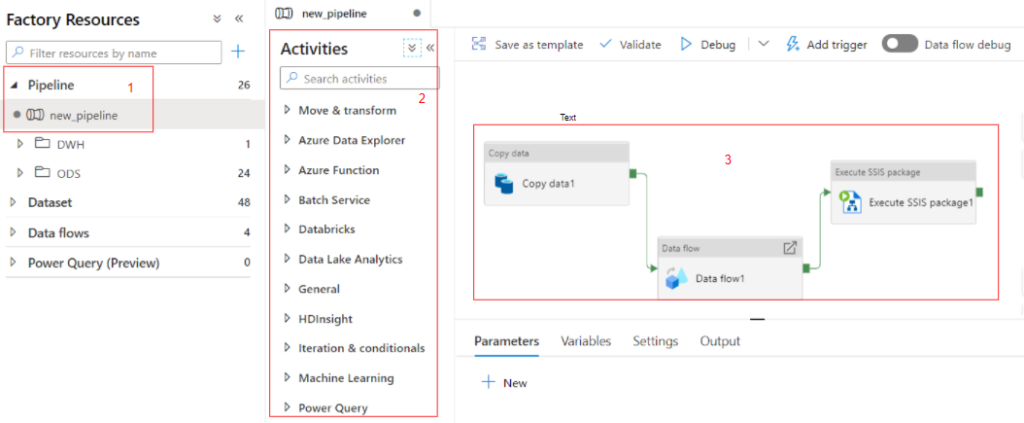
Dataset
Le dataset (source / cible de données) est une vue nommée de données qui pointe ou référence simplement les données que vous souhaitez utiliser dans vos activités en tant qu’entrées et sorties. Data Factory prend en charge de nombreux types d’ensembles de données différents, selon les magasins de données que vous utilisez.
Azure (1) : les sources de données Azure telles que le stockage Azure Blob ou Azure Data Lake.
Base de données (2) : les bases de données telles que MySQL, Oracle ou SQL Server.
Fichier (3) : les systèmes de fichiers tels que FTP ou HDFS
Protocole générique (4) : des protocoles de base tels que le HTTP
NoSQL (5) : les systèmes Not only SQL tels que MongoDB ou Cassandra. À noter que pour pouvoir utiliser des données NoSQL, ADF va nécessiter une mise à plat des données et donc il faudra les structurer fortement.

Data flows
Les mappages de flux de données sont des transformations de données conçues de manière graphique dans Azure Data Factory. Les flux de données permettent aux ingénieurs de données de développer une logique de transformation des données sans rédiger de code. Les flux de données qui en résultent sont exécutés en tant qu’activités dans les pipelines Azure Data Factory.
Le flux de données de mappage fournit une expérience entièrement visuelle sans aucun codage. Vos flux de données sont exécutés sur les clusters d’exécution gérés par ADF pour un traitement des données faisant l’objet d’un scale-out. Azure Data Factory gère intégralement la traduction du code, l’optimisation du chemin et l’exécution de vos travaux de flux de données.
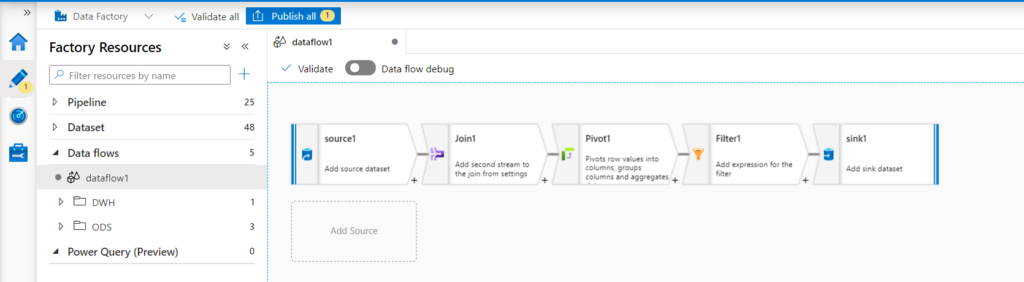
Power Query
L’activité Power Query vous permet de créer et d’exécuter des agrégateurs Power Query pour exécuter du data wrangling à grande échelle dans un pipeline Data Factory. Vous pouvez créer un agrégateur Power Query à partir de l’option de menu Nouvelles ressources ou en ajoutant une activité Power Query à votre pipeline.
Pour atteindre l’échelle avec votre activité Power Query, Azure Data Factory traduit votre script M en script de flux de données afin que vous puissiez exécuter vos Power Query à grande échelle à l’aide de l’environnement Spark.
Monitoring
Les applications cloud sont complexes, et comprennent de nombreux éléments mobiles. Les analyses fournissent des données pour vous aider à garantir que votre application reste opérationnelle et soit exécutée en toute intégrité.
Les analyses vous aident également à éviter des problèmes potentiels et à résoudre les problèmes précédents. Vous pouvez utiliser les données de surveillance pour obtenir des informations détaillées sur votre application.
Manage
Les avantages
- Un service délocalisé ;
- Une prise en main facile pour des flux simples ;
- Des coûts limités ;
- Un développement ou une gestion de licence qui ne nécessite pas d’installation d’outil ;
- Un ordonnanceur : possibilité de planifier les flux de manière périodique ou un évènement.
Les inconvénients
- Nécessite une attention particulière au démarrage du service : il faut penser à un arrêt automatique sinon les coûts augmentent très vite ;
- Une routine de développement est à acquérir pour stopper les services et éviter des coûts inutiles
- Pour réaliser des flux complexes, la connaissance des langages utilisés est un plus pour surcharger le code lorsque l’interface est incomplète
CONCLUSION DE L’EXPERT
Azure Data Factory est un service d’intégration de données hybride simplifiant l’extraction, la transformation et le chargement (ETL) à grande échelle. C’est un outil visuel, facile à prendre en main et qui s’adapte à la charge de calcul.
Il s’intègre facilement avec les différents services d’Azure garantissant une meilleure sécurité et une haute disponibilité. Il ne joue pas seulement le rôle d’intégrateur, c’est un service capable d’orchestrer toute la chaine de traitement de la donnée jusqu’à sa valorisation.



