Introduction
Les flux ETL sont au cœur de l’architecture d’un SI décisionnel. Bien que certaines structures n’aient pas de besoins particuliers d’optimisation, d’autres sont confrontées à des problématiques de performances.
Ces dernières peuvent avoir un impact sur les données consultées par les utilisateurs finaux et constituent un réel enjeu de fiabilité des données.
ETL SAP Data Services
Un outil ETL (Extract Transform Load) est un utilitaire permettant d’extraire des données d’une ou plusieurs sources puis éventuellement de les transformer afin de les stocker dans un entrepôt de données.
BODS (BusinessObjects DataServices) est l’outil ETL de l’éditeur allemand SAP. Pour une présentation plus détaillée, je vous invite à lire l’article suivant (https://www.decivision.com/blog/etl/les-specificites-de-data-services) permettant d’approfondir les spécificités de SAP Data Services.
Pourquoi optimiser les flux ?
De nombreux Datawarehouse (ou entrepôt de données) sont rafraichis quotidiennement durant les heures creuses d’activités, typiquement la nuit. Ces opérations peuvent entrer en concurrence avec d’autres opérations de maintenance sur les serveurs et ainsi limiter la plage horaire exploitable.
Il est donc essentiel d’effectuer l’ensemble des mises à jour de l’entrepôt de données dans un temps imparti.
Pour de nombreuses structures, ces actions ne sont pas chronophages au point de nécessiter d’optimiser les extractions ETL. En revanche, il est critique pour d’autres de pouvoir réduire au maximum le temps consacré aux opérations ETL.
Bonnes pratiques d’optimisation
Avant d’aborder plus en détail les possibilités d’optimisation offertes par Data Services (BODS), il est bon de rappeler certains principes généraux afin de réduire les temps d’exécution.
Il est recommandé de n’extraire que ce qui est utile à l’entrepôt de données. L’utilisation des clauses WHERE peut permettre de réduire le nombre de lignes à récupérer et donc le temps nécessaire pour ces actions.
Pour les tables ayant une très forte volumétrie, il est conseillé d’explorer la piste des flux de type « delta », c’est-à-dire des flux qui ne chargent que les mises à jour / nouveautés des tables sources. A l’inverse, les flux de type « annule et remplace », qui suppriment et rechargent intégralement une table tous les jours, sont à privilégier dans le cas de tables ayant une faible volumétrie ou pour des bases de données performantes. C’est donc aux développeurs ETL de déterminer au cas par cas la solution la plus rapide et la plus adaptée.
Enfin, il est vivement recommandé de modéliser le flux de façon à faire « travailler » la base de données plutôt que le moteur de l’outil ETL. C’est cette notion que nous allons creuser plus en détail dans la partie suivante.
Optimiser un flux Data Services
Comme évoqué, afin d’optimiser les performances des flux Data Services, il est impératif de déléguer au maximum les opérations d’extractions, transformations et chargement à la base de données. Ce principe se nomme « pushdown » en anglais. Optimiser un flux consiste à se rapprocher au maximum de la notion de « full pushdown », autrement dit, que toutes les opérations soient poussées vers les bases de données.
Afin de vérifier que les traitements sont « pushdown » (partiellement ou totalement), il est nécessaire de consulter le SQL optimisé du Dataflow.
Pushdown_sql

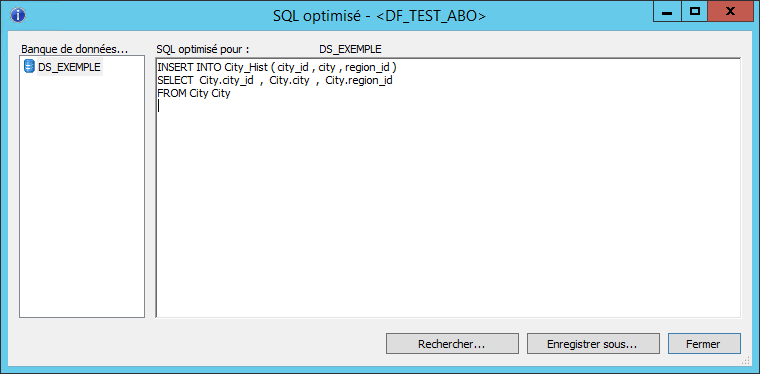
On voit clairement que la requête fait un INSERT INTO … SELECT, c’est-à-dire que seule la base de données intervient pour charger les données, ces dernières ne transitent pas par le JobServer de Data Services pour être traitées.
Ci-dessous, après avoir appliqué une clause WHERE contenant une fonction :
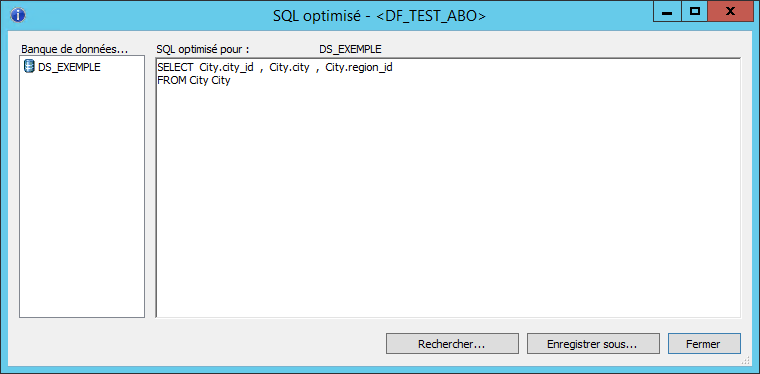
La notion de INSERT INTO … SELECT a disparu au profit d’une simple requête SELECT. Cela signifie que les données seront traitées par le JobServer et que les performances peuvent être dégradées. Plus précisément, Data Services ne connait pas de correspondance entre la fonction employée dans la clause WHERE et la fonction de la base de données associée. Il traitera lui-même les lignes pour appliquer la clause WHERE puis génèrera les instructions INSERT.
Pour contourner cette problématique, la fonction « pushdown_sql » peut être utile s’il existe une fonction de la base de données permettant de reproduire le comportement de la fonction Data Services. Il suffira de réécrire la clause WHERE en intégrant la fonction « pushdown_sql » et d’utiliser la fonction de BDD plutôt que BODS. Les opérations seront alors entièrement traitées par la base de données et non pas par le JobServer.
Data_Transfer
L’élément Data_Transfer permet de pousser des opérations à la base de données en utilisant des tables ou fichiers temporaires pour des opérations intermédiaires qui seraient normalement effectuées par le JobServer.
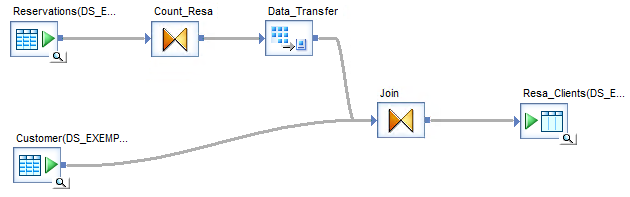
Ci-dessous, le Dataflow permet de compter le nombre de réservations par client (Count_Resa) puis de croiser ces informations (Join) avec la fiche client pour stocker ces données dans une table cible (Resa_Clients).
Le SQL optimisé se décompose en deux requêtes :
- Une première qui opère l’agrégation et le Group By
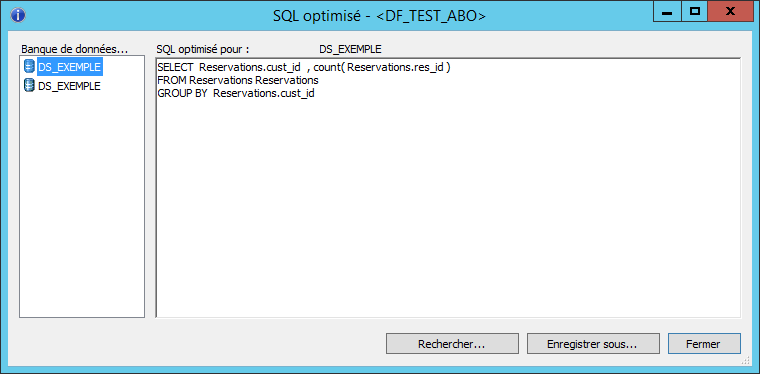
- La seconde qui récupère les données de la fiche client
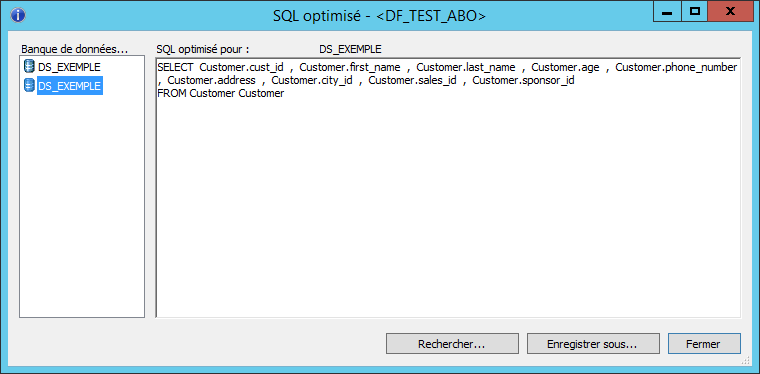
Ainsi, la jointure entre l’agrégation et la fiche client n’est pas faite en SQL mais par le JobServer. Les jointures non déléguées à la base de données étant chronophages et consommatrices de ressources, il peut être intéressant de contourner ce type de situation.
L’utilisation de l’élément DataTransfer permet de transférer les opérations intermédiaires dans une table temporaire. Dans notre cas, les données agrégées seront stockées dans une table tampon puis cette dernière sera jointe avec la table contenant les fiches clients.
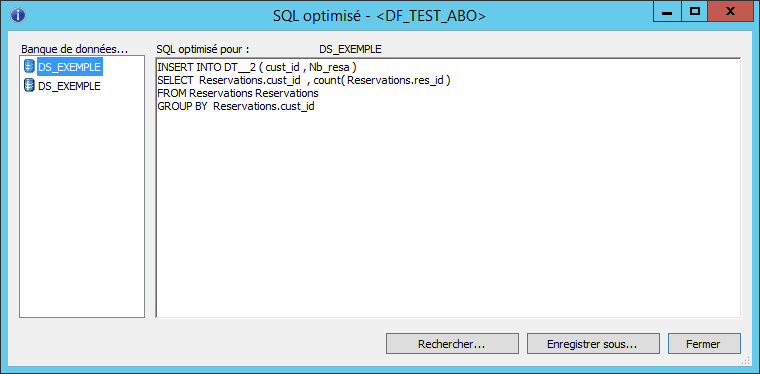
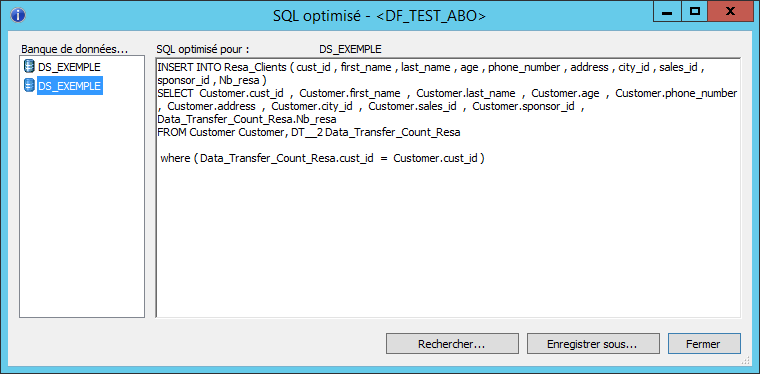
Nous retrouvons bien les notions de INSERT INTO … SELECT ainsi que la jointure.
L’élément Data_Transfer est particulièrement utile dans le cas de Dataflow « complexe » avec de multiples transformations intermédiaires (enchainement d’éléments Query).
Autres axes d’optimisations possibles
Les exemples concernant la fonction pushdown_sql et l’élément Data_Transfer sont non exhaustifs et ils existent une multitude de cas où ils sont utilisables.
D’autres éléments permettent d’optimiser les flux :
- Les paramètres des tables sources permettent d’augmenter la taille d’extraction du tableau et donc de modifier le nombre de lignes qui est récupéré par chaque paquet d’extraction. En effet, BODS extrait les données par paquet, en augmentant la taille de celui-ci, on peut diminuer les « allers-retours » et diminuer le temps d’extraction.
Il est vivement conseillé de faire différents tests afin de trouver le réglage optimal. Une taille trop petite augmentera le nombre d’allers-retours et donc le temps de chargement, à l’inverse, une taille trop grande saturera les paquets et ces derniers mettront plus de temps à être traité.
- Les paramètres des tables cibles contiennent de multiples options pour optimiser les chargements
- Le Bulk Loader permet de charger plus efficacement un grand volume de données en s’affranchissant de certains logs de bases de données ou des contraintes d’intégrités
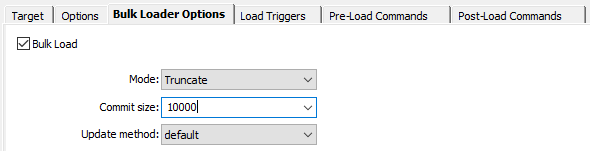
-
- Le nombre de lignes entre chaque Commit. Plus ce nombre est grand, plus des lignes sont insérées entre chaque instruction Commit. Tout comme les paramètres de taille d’extraction du tableau, il est conseillé de trouver un juste équilibre car un paramétrage trop faible ou trop élevé impactera les performances négativement
- Autoriser les instructions MERGE ou UPSERT peut permettre de mettre à jour plus rapidement des lignes existantes
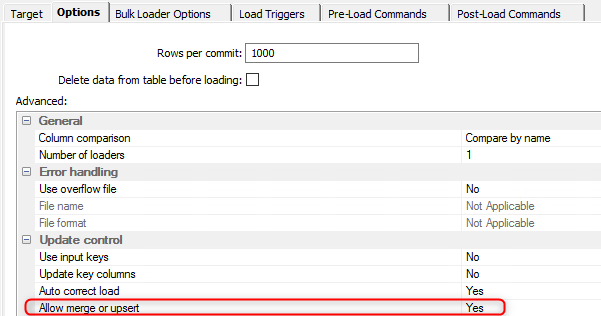
- L’utilisation d’index peut permettre de diminuer les temps de mises à jour des tables
- Il est conseillé d’utiliser des bases de données sur un même réseau pour diminuer les délais de transferts. De même, il est recommandé d’utiliser les mêmes serveurs de bases de données pour accroitre les possibilités de full-pushdown SQL. Le cas échéant, il est possible de mettre en place des Datastore liés.
CONCLUSION DE L’EXPERT
L’optimisation d’un flux Data Services peut être faite via de multiples méthodes. Elles ne sont pas toutes toujours pertinentes et l’expérience du développeur ETL jouera un rôle crucial dans le choix de la ou des modifications à apporter au flux.
De manière générale, il est recommandé lorsque cela est possible de modéliser les flux de façon à faire « travailler » la base de données plutôt que le moteur de l’outil ETL.



