Introduction
SAP HANA intègre des fonctionnalités permettant de stocker, traiter, partager et manipuler le traitement de données géospatiales.
Pour y parvenir, SAP HANA intègre un moteur de calcul dédié et permet de traiter les données sous forme de vecteurs 2D/3D, de points, et ensembles de points (ligne), ou encore de polygones simples et composés.
Dans cet article, nous prendrons pour exemple une société souhaitant représenter graphiquement les zones géographiques pour lesquelles les ventes sont les plus importantes.
Types de données
Pour pouvoir manipuler les données géospatiales, de nouveaux types de données ont été créés :
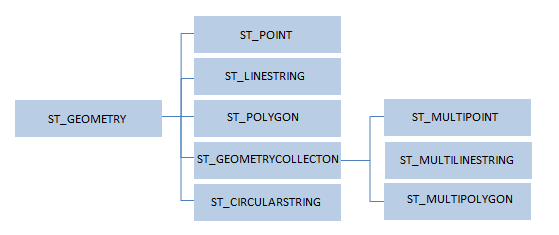
| Type | Description |
| ST_GEOMETRY | Il s’agit du « super-type » pour tous les types de données spatiales |
| ST_POINT | Désigne un seul point de localisation dans l’espace. Ce point a toujours deux coordonnées : X,Y |
| ST_POLYGON | Représente un espace. Dans les SIG, les polygones représente généralement des territoires (régions, départements…) |
| ST_LINESTRING | Géométrie avec une longueur mais pas d’air. Utilisé généralement pour représenter une route, une rivière… |
| ST_MULTILINE | Collection de linestrings. Utilisé par exemple pour représenter un réseau routier |
| ST_MULTIPOINTS | Ensemble de points |
| ST_MULTIPOLYGON | Collection de polygones. Utilisé par exemple pour représenter un pays et ses régions |
| ST_CIRCULARSTRING | Ensemble d’arcs de cercle composé de trois points, un début, un intermédiaire et une fin. |
Fonctions SQL pour les données géospatiales
Des fonctions SQL spécialisées sont disponibles pour manipuler ces types de données. Nous pouvons notamment citer celles-ci :
| Fonction | Description |
| [geo1].ST_EQUALS([geo2]) | Test si une géométrie est égale à une autre (au niveau spatial) |
| [geo1].ST_CONTAINS([geo2]) | Renvoie 1 (true) si une les valeurs d’une géométrie contiennent celles d’une autre. A utiliser dans un système de références « Flat-Earth »*. |
| [geo1].ST_COVERS([geo2]) | Renvoie 1 (true) si une des valeurs d’une géométrie contient celle d’une autre. A utiliser dans un système de références « Round-Earth »**. |
| [geo1].ST_WITHIN([geo2]) | Renvoie 1 (true) si une les valeurs d’une géométrie sont contenues dans celles d’une autre. A utiliser dans un système de références « Flat-Earth »*. |
| [geo1].ST_COVEREDBY([geo2]) | Renvoie 1 (true) si une les valeurs d’une géométrie sont contenues celles d’une autre. A utiliser dans un système de références « Round-Earth »**. |
| [geo1].ST_WITHINDISTANCE([geo2], distance) | Test si deux géométries sont à une certaine distance l’une de l’autre |
| [geo1].ST_DISTANCE([geo2]) | Retourne la plus petite distance entre deux géométries |
| ST_Area | Calcul l’air d’un polygone ou d’un multi-polygone |
| ST_AsGeoJSON | Retourne un string représentant la géométrie dans un format JSON |
| ST_AsText | Retourne la représentation textuelle d’une valeur ST_GEOMETRY |
| ST_Buffer | Retourne une valeur ST_GEOMETRY qui représente tous les points qui sont à une distance définie d’un point donné. |
| ST_ConvexHull | Retourne l’enveloppe convexe d’un point ST_GEOMETRY |
| ST_Intersection | Retourne la valeur qui représente l’intersection de deux géométries |
| ST_IsEmpty | Détermine si une géométrie représente un ensemble vide. |
*Flat earth: représentation 2D de la terre
**Round earth: représentation 3D de la terre
En complément, d’autres fonctions nous permettent de faire du clustering via des requêtes SQL.
Le clustering est une méthode qui vise à regrouper des points en clusters en fonction de certains critères. Un cluster constitue un sous ensemble des données d’origine.
Pour illustrer cette définition, voici trois exemples d’algorithme couramment utilisés en clustering :
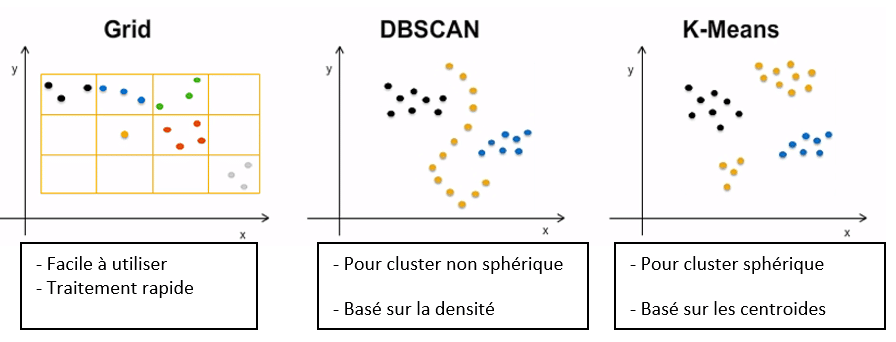
Sur la plateforme HANA, il est possible d’utiliser ces algorithmes avec de simples requêtes SQL.
En reprenant notre exemple, nous pouvons utiliser l’algorithme K-means pour déterminer les zones (clusters) où les ventes sont plus importantes :
Table utilisée :
CREATE COLUMN TABLE « SAPHANADB ». »FORMATION_GEOMETRIE » (
id_magasin INTEGER,
nom_magasin NVARCHAR(50),
ventes_magasin INTEGER,
localisation_magasin ST_POINT);
On notera l’utilisation du type ST_POINT (qui correspond au champ qui contient les coordonnées géospatiales, latitude longitude, de nos magasins dans notre exemple)
En exécutant un algorithme K-MEANS sur les données, nous obtenons les résultats suivants :
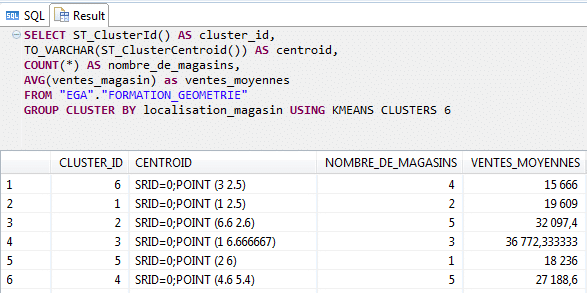
L’algorithme est paramétré pour grouper les magasins en 6 clusters (nos zones de ventes) d’après leurs coordonnées (ST_POINT) et calculer la moyenne des ventes et le nombre de magasin par cluster. Le centroid, correspond au point représentant le centre du cluster.
Vous pouvez également inclure une clause de type HAVING COUNT(*) > 5 pour que l’algorithme ne créé que des clusters d’au moins 5 magasins.
Il est aussi possible de récupérer l’enveloppe du cluster via la commande ST_ClusterEnvelope() :
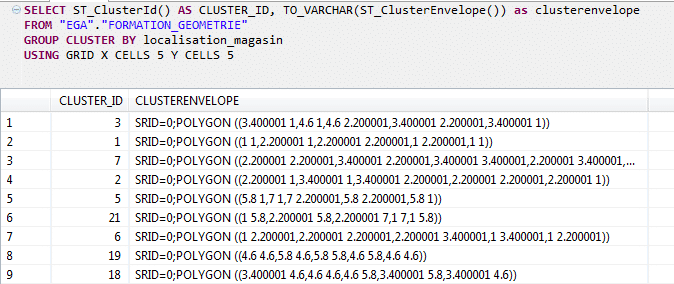
Cette fonctionnalité nous permet de récupérer le « contour » de nos clusters et avoir une représentation graphique de nos zones de ventes sous forme de polygone.
Ces données, stockées sous forme de ST_PYLYGON, peuvent être transformées en XML pour générer une forme « graphique ».
Pour ce faire nous utiliserons la fonction .ST_AsSVG() :
SELECT « SHAPE ».ST_AsSVG() from « departements-20170102 » where « code_insee » = ’29’ ;
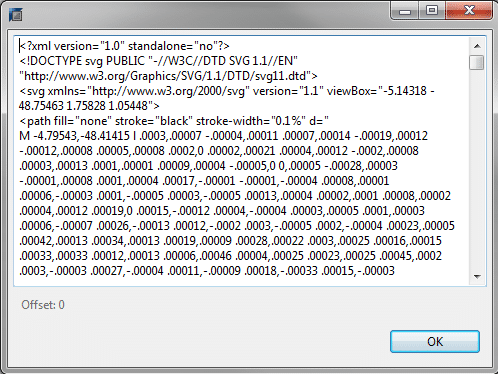
Note : le fichier utilisé est un shapefile téléchargé sur le site de l’insee. Puis chargé dans une table « departements-20170102 » de la base HANA. Le résultat aurait été identique si nous avions utilisé la fonction ST.AsSVG sur nos contours de clusters.
Cette fonction vous génère une figure représentant une géométrie sous forme de XML.
Ce XML peut être exporté vers un fichier HTML pour obtenir une visualisation graphique :
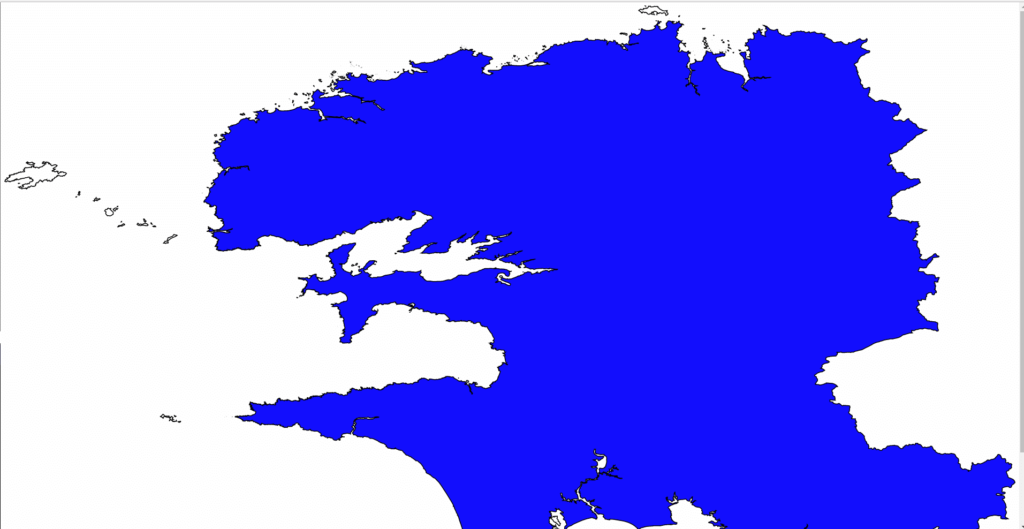
Cette manipulation peut bien entendu être automatisée via un script xsjs sur la plateforme HANA.
Vous pouvez trouver la liste complète des fonctions spatiales à cette adresse :
Modélisation spatiale
Il est aussi possible de créer des modèles (vues HANA) géo-spatiaux grâce à de nouveaux types de jointures. Ces jointures se comportent comme des fonctions spatiales.
Créez une vue de calcul, ajoutez-y des tables contenant des types de données spatiale et créez une jointure :
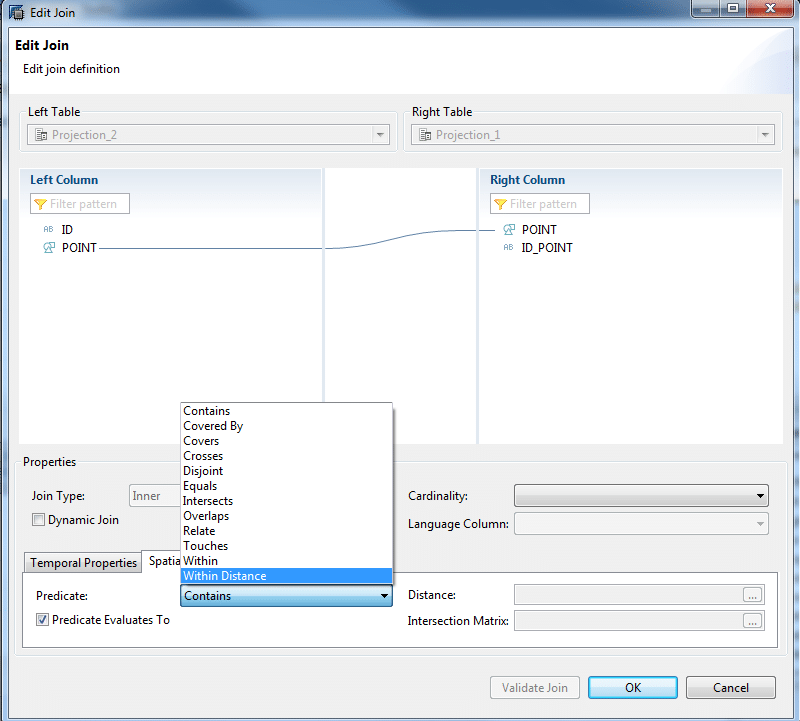
De nouveaux prédicats vous sont proposés : Contains, Covered By, Covers, Crosses, Disjoint, Equals, Intersects, Overlaps, Relate, Touches, Within et Within Distance.
Si vous choisissez le prédicat « Within Distance » vous pouvez paramétrer la distance voulue, soit de manière fixe, soit par « input parameter » :
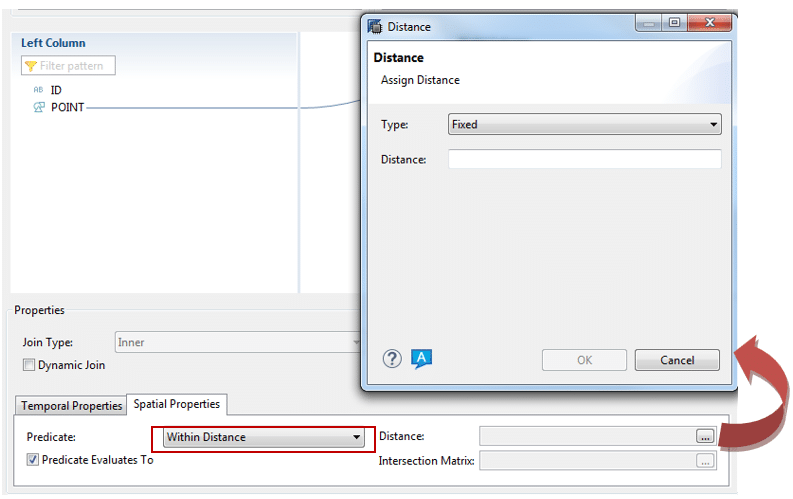
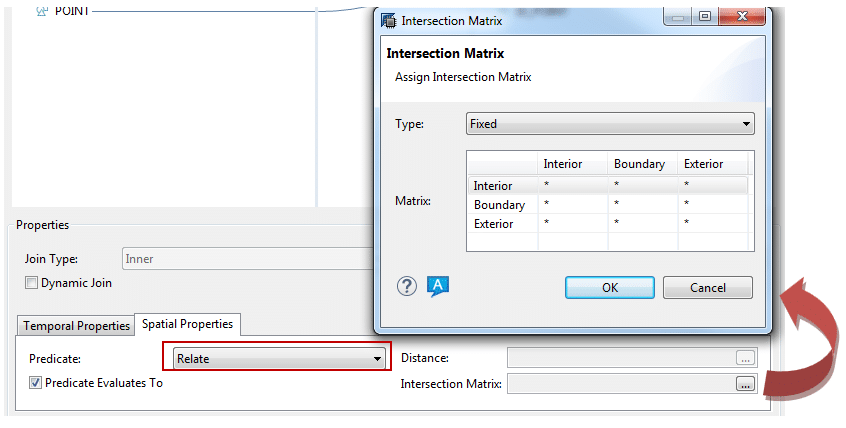
En revanche, si vous choisissez le prédicat « Relate », il vous faudra renseigner manuellement (ou via input parameters) une matrice d’intersection :
CONCLUSION DE L’EXPERT
La plateforme SAP HANA propose de nombreuses fonctionnalités dédiées au traitement et à l’analyse des données géospatiales. Elles permettent de réaliser de nouvelles analyses, peu courantes dans le monde de la BI, la plupart du temps, on retrouve ces fonctions dans les SIG.
Avec un peu de développement, il est même possible, via les services XS, de créer un SIG maison temps-réel, qui repose sur les données stockées dans votre base HANA et ainsi enrichir vos outils d’analyse de données.



