Smart Data Integration : Répliquez vos données en temps réel sur SAP HANA
Rédigé par
Steven VERBRAEKEN
Introduction
Le SDI (Smart Data Integration) est un outil complémentaire à SAP HANA. Il permet d’intégrer des données dans SAP HANA en temps réel. Il s’agit d’un outil faisant office d’interface entre les sources de données hétérogène et HANA doté de fonctionnalités ETL (fédération et de réplication de données en batch ou en temps réel).
Il est aussi possible de virtualiser les tables, et de ne pas stocker la donnée dans la base cible, afin de gager en espace disque ou mémoire. Avant son introduction, il fallait utiliser Data Services pour l’intégration ETL et SLT/SRS pour la réplication de données. Ces fonctionnalités sont désormais regroupées dans SDI.
Le SDI contient des adaptateurs pour tous les formats de fichiers, permettant de réaliser des extractions de données rapides à mettre en place. S’il en manquait, le cas échéant, on peut utiliser le SDK intégré pour en créer.
Afin d’utiliser SDI, il faut au préalable installer l’outil Data Provisioning Agent.
Installation et configuration du DPA (Data Provisioning Agent)
Installation
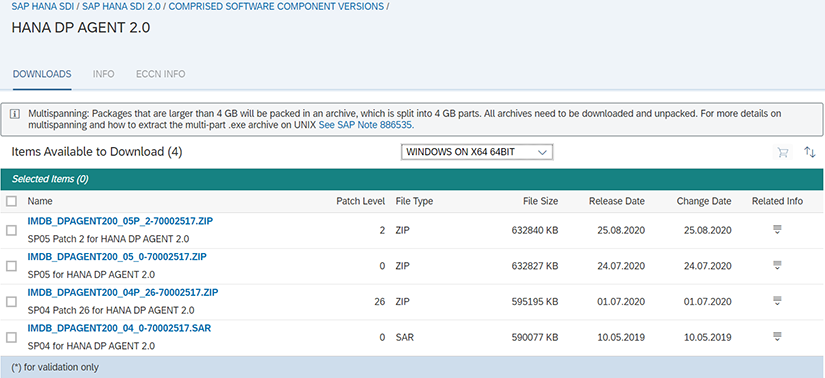
Téléchargez les sources sur le site du support SAP en suivant le schéma SAP HANA SDI > SAP HANA SDI 2.0 > COMPRISED SOFTWARE COMPONENT VERSIONS > HANA DP AGENT 2.0 puis téléchargez IMDB_DPAGENT200_05_0-70002517.ZIP
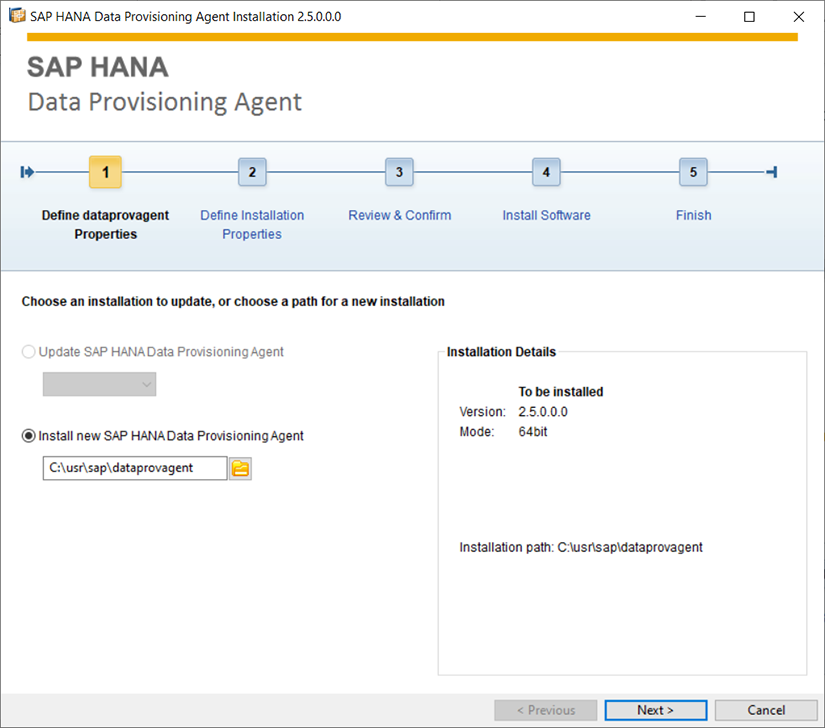
Dézipper et faire clique droit > installer en tant qu’administrateur.
Cliquer sur Next, puis Install.
Configuration
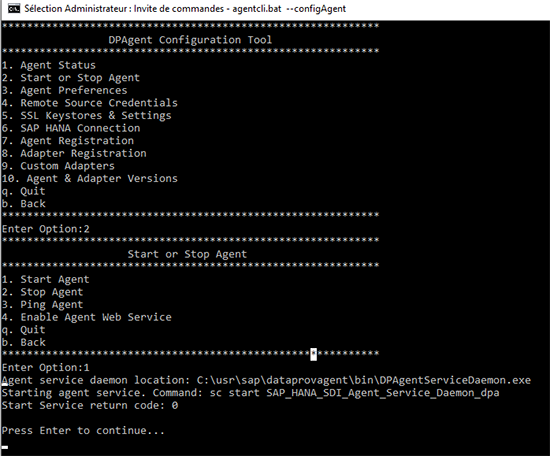
Après installation, vérifier que le service est bien démarré en allant sur l’outil Windows « services.msc » et en démarrant le service « SAP_HANA_SDI_Agent_Service_Daemon_DPA ».
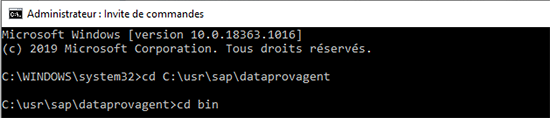
La configuration du DPA se fait en ligne de commande.
Choisir « option1 »
Renseigner la série de paramètres suivants :
Enter Use encrypted JDBC connection[true] : true
Enter Host Name : ip du serveur
Enter Port Number : port du serveur
Enter Agent Admin HANA User :user
Enter Agent Admin HANA User password :password
Enter HANA User Name for Agent Messaging : DPA
Do you want to create a new SAP HANA user with the specified Agent XS HANA User credentials ? :false
Lorsque vous aurez tout saisi, la fenêtre de commandes devrait afficher la chose suivante :
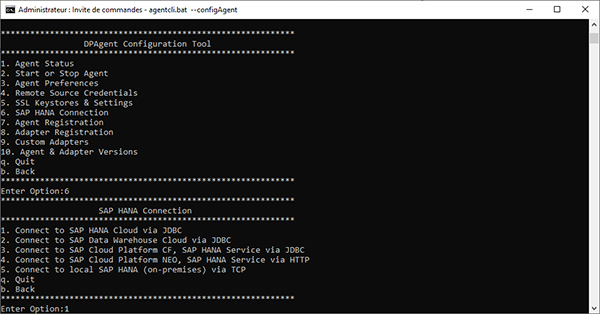
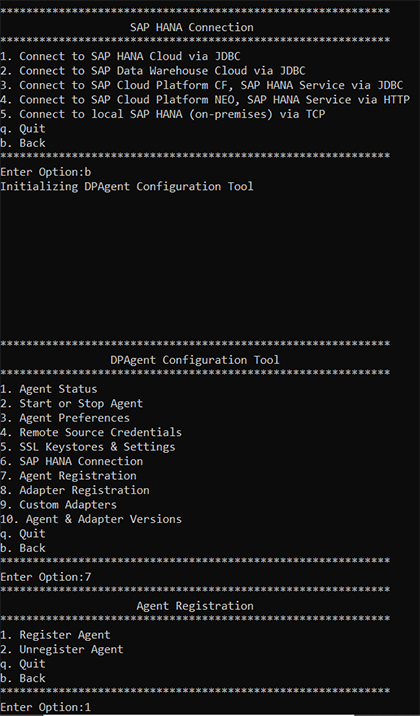
Nous allons ensuite procéder à l’enregistrement de l’agent. Entrez « b », puis choisissez l’option 7 puis 1
L’Agent Host Name devrait porter le même nom que la machine déployant le DPA. Celui-ci devrait être automatiquement renseigné ici :
Appuyez sur « Enter ». L’agent de configuration vous demandera un « Agent Host Name ». Ce dernier sera rempli automatiquement aussi. Vous devriez obtenir ce résultat :
Pour finir, enregistrez un adaptateur en utilisant l’option « 8 » après avoir retourné au menu principal.
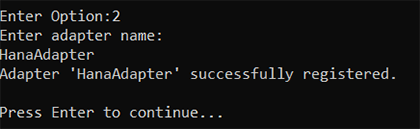
Entrez l’option « 2 » (Register Adapter), tapez « Hana Adapter » et Entrée :
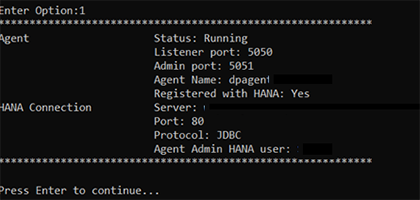
Afin de vérifier la bonne mise en place de l’agent, retournez au menu principal et entrez l’option « 1 » :
Exemple de flux de réplication de tables
Le but de cet exemple est de répliquer une table d’un system « on premise » à un system « hana cloud ».
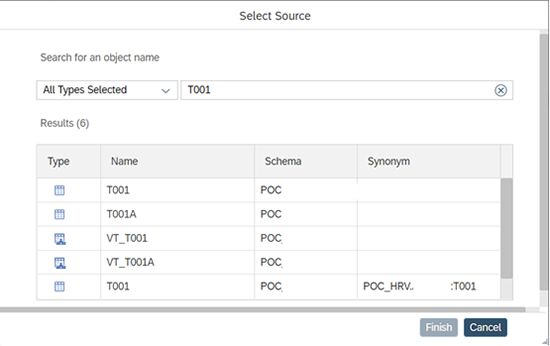
On prendra dans ce cas la table T001. Pour cela, il faudra d’abord virtualiser la table, puis la rendre physique dans le schéma cible à travers un « flowgraph ».
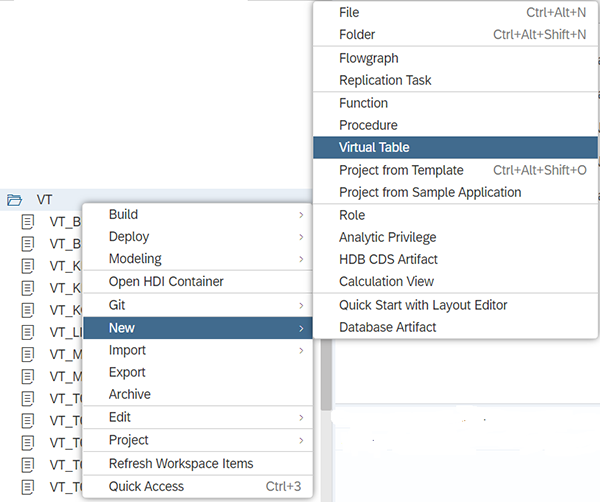
Pour créer la table virtuelle, il faudra se connecter à l’IDE de Hana Cloud. Dans votre workspace, créer un dossier « VT » pour vos tables virtuelles. Puis, faire clic droit sur le dossier et créez lune table virtuelle comme suit :
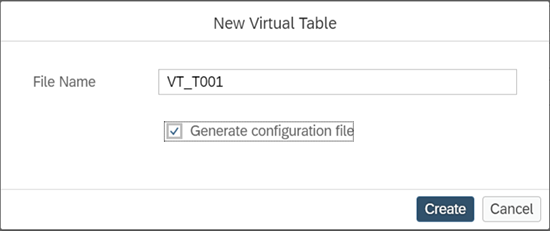
Nommez la VT « VT_T001 »
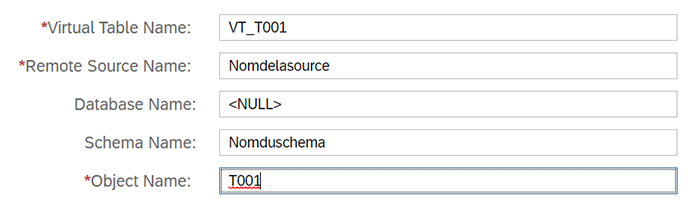
Remplissez les champs suivants
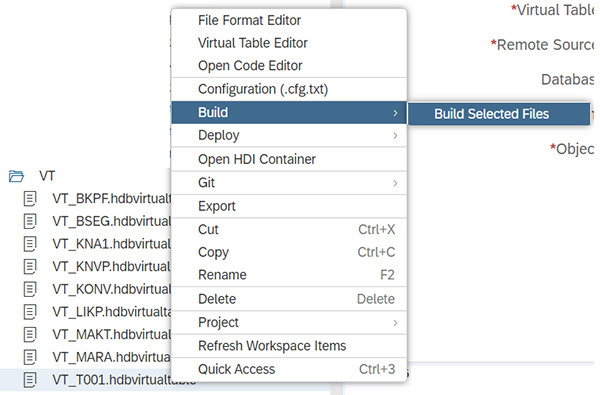
Sauvegardez votre fichier (Control + S) puis « Build ».
Après avoir fait Build, vous devriez avoir le message suivant dans les logs :
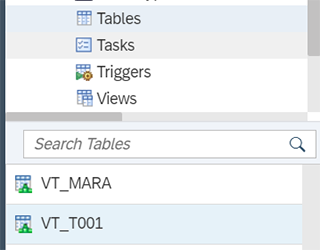
Confirmez en vous rendant dans le Database Explorer
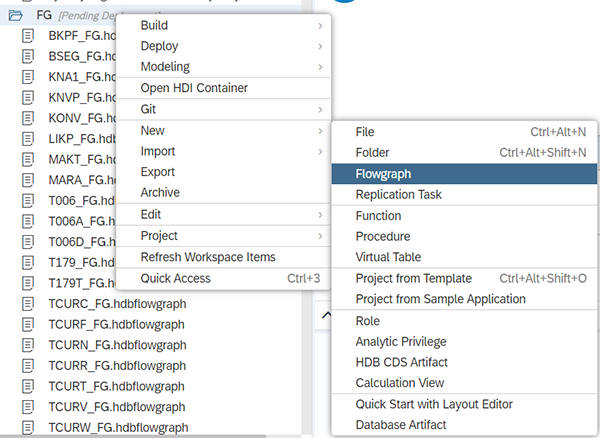
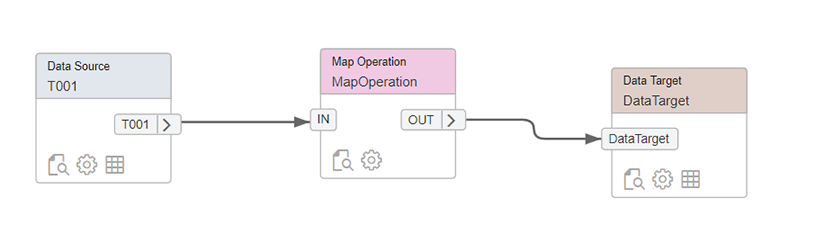
Puis, créez le flowgraph T001 :
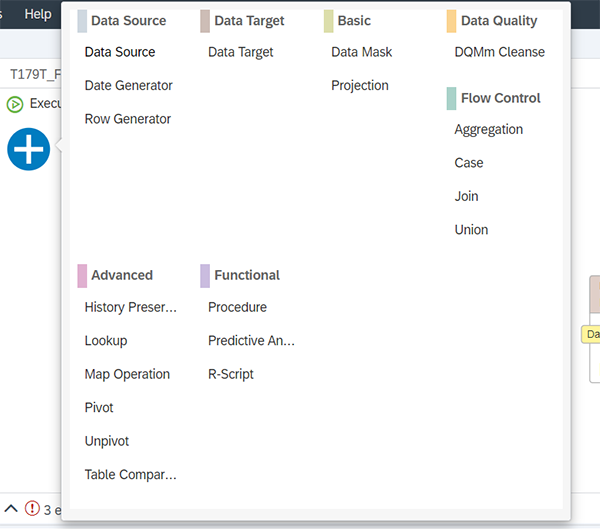
Placez les éléments « DataSource », « MapOperation » et « DataTarget » :
Ouvrez DataSource en cliquant sur l’engrenage, sélectionnez DataObject et cherchez « VT_T001 » :
Une fois l’opération réalisée, cliquez sur « Apply » en haut à droite. Ensuite, liez les trois composants comme suit :
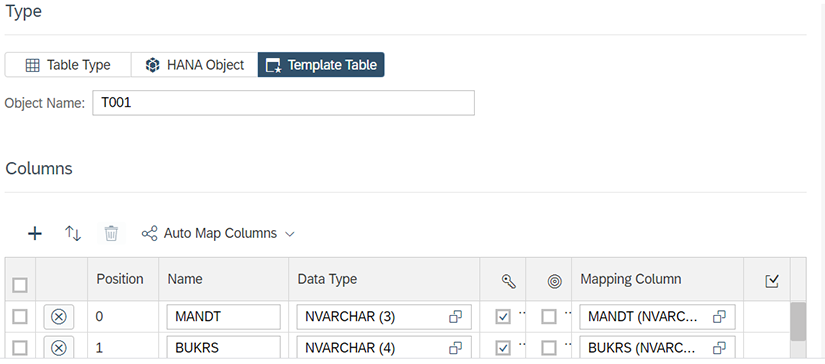
Puis, cliquez sur l’engrenage de Data Target, sur Template Table et nommez l’objet T001 :
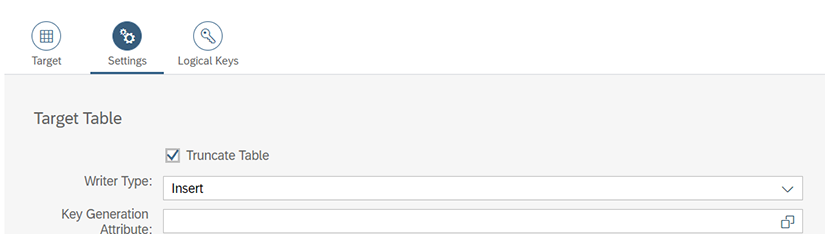
Ouvrez Settings et complétez le formulaire comme suit :
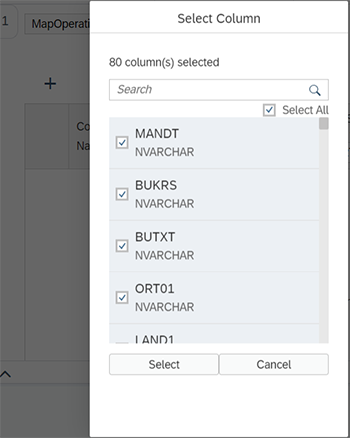
Pour finir, cliquez sur l’engrenagede MapOperation, puis sur le « + » et ajoutez toutes les colonnes souhaitées :
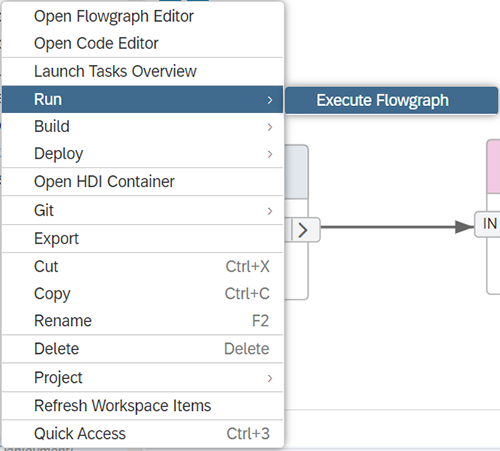
Cliquez sur « Apply ». Enregistrez le fichier avec un « Control + S » puis buildez-le. Une fois ces étapes réalisées, lancez le flowgraph :
Une fois votre flowgraph terminé, vous devriez retrouver votre table :
CONCLUSION DE L’EXPERT
Avec SDI, on peut, à travers des outils SAP HANA, répliquer, transférer, transformer ou virtualiser des tables présentes dans vos bases source dans/vers une plateforme HANA.
Ainsi, pour des entreprises possédant des architectures de SI complexes et hétérogènes en termes de sources de données, cet outil vient faciliter le transit de données vers le système HANA (comme le ferai un outil de type ETL). Avec les options de virtualisation ou temps réel les performances peuvent être optimisées.
Cet outil permet aussi d’unifier l’accès aux données ainsi que les moyens de reporting dans l’entreprise en concentrant toutes les données au travers d’une seule plateforme « SAP HANA ».
L’outil permet d’ailleurs d’accéder à des données, sans devoir les ramener ou les copier de la source vers la destination au travers d’exports, ceci peut être bénéfique dans le cas de données sources volumineuses.