Introduction
La vue de calcul, ou « Calculation View », est l’un des trois principaux modèles d’information disponibles sur la plateforme SAP HANA.
Ce modèle d’information est celui qui offre la plus grande souplesse en termes de modélisation puisque qu’il supporte un grand nombre de sources de données (des tables de base de données, des vues d’attribut, des vues d’analyse et d’autres vues de calcul, des scripts, des procédures stockées, des tables fonction, …).
Il est aussi possible d’exécuter des calculs complexes ne pouvant pas être traités par les autres modèles d’information.
Créer une vue de calcul
- Dans l’outil SAP HANA Studio, choisissez le nom du package sous lequel vous souhaitez créer une vue de calcul.
- Cliquez droit sur Package → « New » → « Calculation View » :
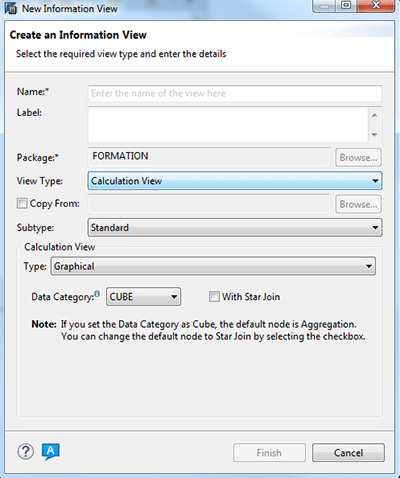
Il existe plusieurs types de vue de calcul : ces vues ne peuvent être que de sous-type « Standard » ou « Time », et il n’est pas possible de créer une vue dérivée d’une Calculation View.
Type Standard : dans ce sous-type, vous pourrez créer des vues « graphiques » et « scriptées ».
Type Time : dans ce sous-type vous ne pourrez créer qu’une vue de type « Graphique » et non « SQL Script ».
Pour les vues de calcul, des propriétés peuvent être éditées :
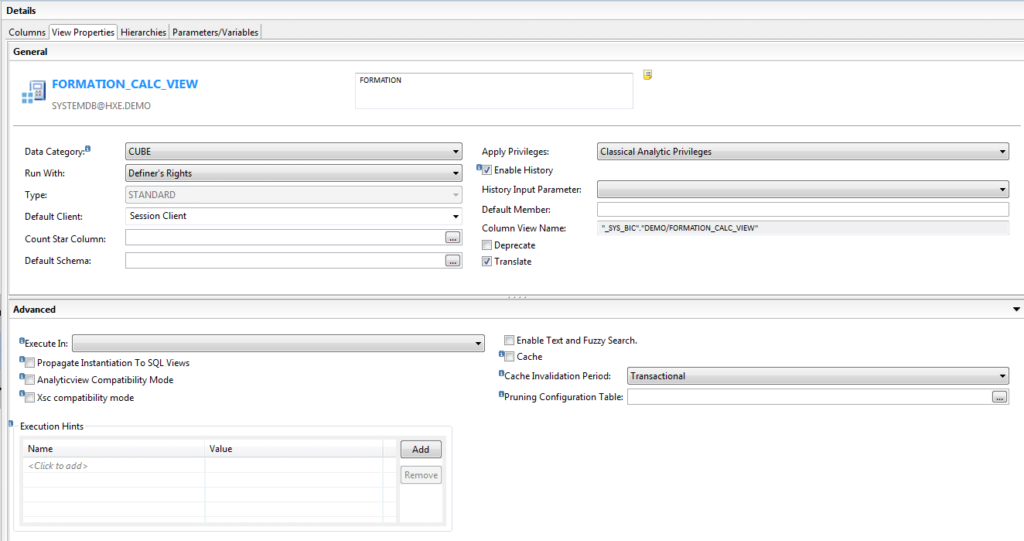
- « Data Category » : Cube, Dimension
- « Type » : Standard, Time
- « Default Client » : Correspond au champ MANDT des tables ECC / S4. Il est possible d’attribuer un client spécifique à un utilisateur, ce qui engendrera un filtre automatique sur les données.
- « Count Star Column » : Définit la colonne à utiliser pour connaitre le nombre de lignes contenues dans la vue
- « Execute In » : Définit comment appliquer la sécurité lors de l’exécution d’une vue de calcul basée sur les scripts.
- « Default Schema » : Détermine le schéma à utiliser quand celui-ci n’est pas paramétré dans la source
- « Apply Privileges » : Spécifie le type de « Analytic privilege » à appliquer lors de l’exécution d’une vue, sécurité intégrée à la plateforme SAP HANA
- « Enable History » : Détermine si la vue supporte les requêtes sur les historiques de tables
- « History Input Parameter » : Détermine quel contrôle d’entrée doit être utilisé pour spécifier le timestamp utilisé lors de requête historique
- « Column View Name » : Champ correspondant au nom complet de la vue dans le schéma _SYS_BIC
- « Propagate Instantiation to SQL Views » : Si votre vue est utilisée par une autre vue, cette option vous permet d’ignorer les attributs qui ne sont pas repris dans la couche suivante.
- « Enable Text and Fuzzy Search » : Autorise l’utilisation de méthodes de recherche de texte sur le contenu de la vue.
Principaux avantages d’une vue de calcul :
- Les vues de calcul supportent les modèles OLTP et OLAP.
- Ils aussi peuvent soutenir des expressions complexes telles que Case, Counter, IF.
- Les vues de calcul utilisent les privilèges analytiques qui sont utilisés pour restreindre l’utilisateur à afficher les données pour lesquelles il autorise la sécurité.
Vue de calcul Standard graphique
| Types de vues de calcul | Propriétés | Noeud supérieur (par défaut) |
| Blank | Ne supporte pas d’opérations multidimensionnelles et n’est pas exposé aux outils client | Projection |
| DIMENSION | Ne supporte pas d’opérations multidimensionnelles | Projection |
| CUBE | Destinée à l’analyse de données multidimensionnelles | Agrégation |
| Cube avec Star Join | Similaire au CUBE, sauf que le nœud supérieur est une jointure en étoile où il est possible de joindre des vues de calcul de type dimension | Star Join |
Blank / Dimension : Ces vues de calcul ne peuvent pas traiter les mesures et toutes leurs colonnes sont considérées comme des attributs. Cependant, vous pouvez utiliser ces vues comme sources de données dans d’autres vues de calcul.
Cube / Cube avec Star Join : Les cubes sont visibles par les outils de création de rapports. Les vues de calcul de type Cube ou Cube avec Star Join sont à utiliser pour traiter les mesures, agrégations et opérations de calcul diverses. Ce type de vue supporte les opérations de jointures, d’union, de projection, d’agrégation, et de Rank. Il permet d’ajouter ces nouvelles opérations à votre scénario. Une agrégation sur ce type de vue se traduira par un select distinct.
Exemple : Cube avec Star Join
Choisissez le sous-type « standard », la « data category » « cube with star join » puis créez votre vue. Le dernier nœud du scénario sera un « Star Join ». Par un clic-droit, il est possible de changer ce nœud en projection ou agrégation, puis si besoin, de nouvelles opérations sont affichées et utilisables dans le menu à gauche de l’interface :
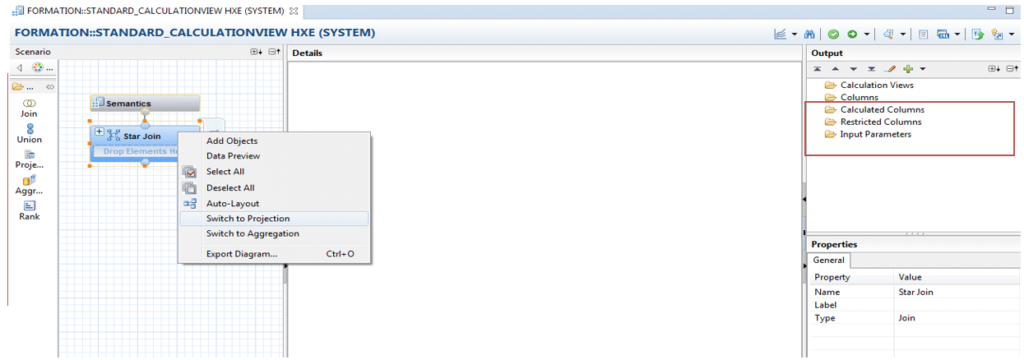
- Projection : Utilisée pour filtrer les données depuis la table/vue ou pour obtenir un sous-ensemble des colonnes d’une table/vue
- Join : Utilisé pour requêter les données de deux ou plus sources de données
- Star join : Utilisé pour joindre les attributs dans le dernier nœud de création d’un cube.
- Union : Utilisé pour combiner les données provenant de plusieurs sources de données (deux ou plus).
- Agrégation : Utilisé pour agréger les données en fonction d’un attribut.
- Rank : Utilisé pour ordonner les données en fonction d’un Top N sur une mesure.
La vue de calcul supporte un grand nombre de sources de données :
- Des tables en ligne ou en colonne provenant de la même base de données ou de base de données différentes mais du même système
- Des documents Core Data Services (document de création de modèle de données persistant)
- Des vues SQL script et Des vues de calcul basées sur des scripts. Ces vues sont à utilisées lorsqu’une logique complexe est nécessaire (utilisation de « case » ou de « if then else » ou de boucles).
- Des vues de calcul graphiques (de la même base de données ou de base de données différentes mais du même système HANA, dans le cas d’un système multi database container). A noter que seules les vues de calcul de type « Dimension » peuvent être intégrées dans la star join.
- Des tables de fonctions et des tables virtuelles (données fournies au travers du Smart Data Access).
- Des vues d’analyses.
Exemple : Opération rank
La fonction « Rank » est utilisée lorsque vous souhaitez afficher uniquement certaines lignes supérieures ou inférieures de votre jeu de données.
Sélectionnez votre fondation de données, puis faites un clic droit > « switch to aggregation » Faites ensuite un glissé-deposé de l’élément « rank » depuis la palette vers votre scénario :
Ajoutez une projection et ensuite une source dans votre projection. Cette source peut être une vue d’analyse, une table, ou une vue de calcul. Choisissez un tri ascendant ou descendant, votre mesure, votre attribut de référence :
Le nœud « Rank » dispose d’options spécifiques :
- Le « Sort Direction » vous permet de définir si vous voulez les N premiers enregistrements (Descending) ou les N derniers (Ascending).
- Threshold : Vous permet de définir un seuil. Celui-ci peut être fixe ou basé sur un contrôle d’entrée.
- Order By : Liste déroulante dans laquelle vous pouvez choisir sur quelle colonne sera basé le tri.
- Partition By Column : Détermine par quel attribut la table doit être partitionnée. (Comparable à un group by)
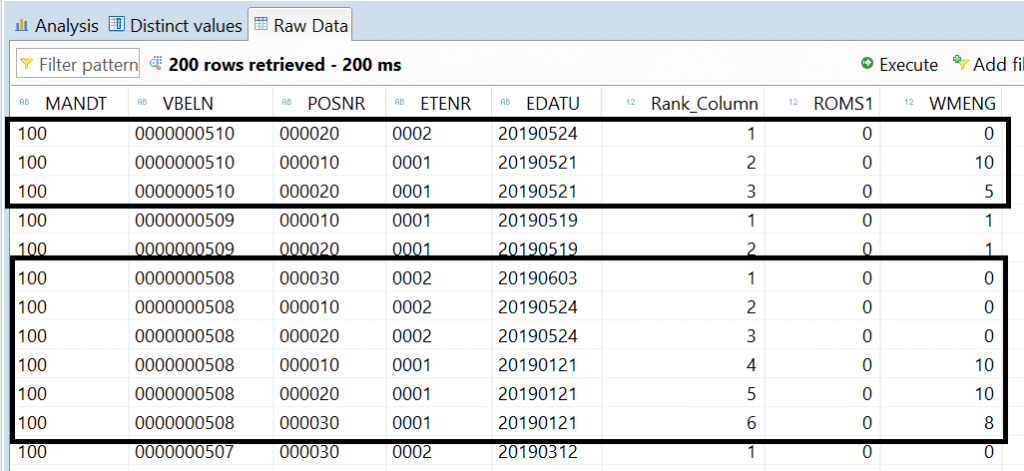
Déployez ensuite votre vue, et faites un « data preview » : Les données sont triées par date en fonction de la mesure WMENG.
Exemple : Union
Le moteur réalise une jointure externe complète sur plusieurs objets sources et crée en sortie un seul objet en combinant leur contenu. Dans une vue de calcul, sélectionnez les projections et union, sélectionnez ensuite votre nœud d’union et cliquez sur le ‘+’ vert dans la partie droite :
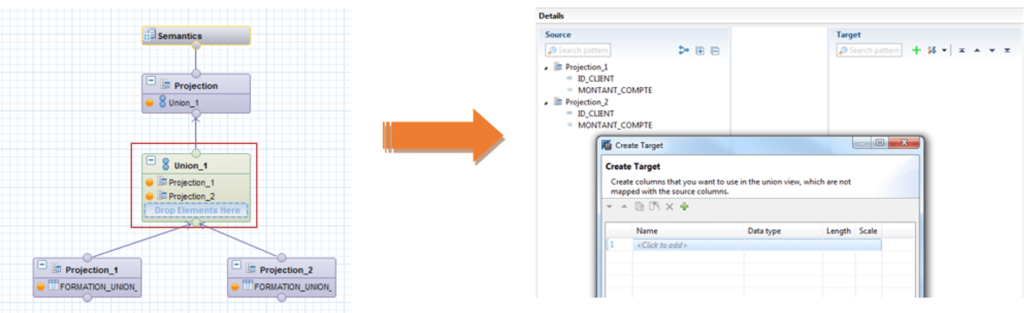
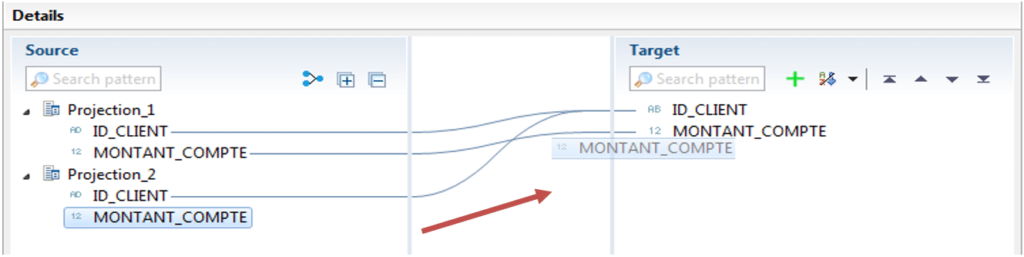
C’est via cette fenêtre que le schéma cible de l’union doit être spécifié. Après avoir créé votre schéma cible, créez le mapping par glissé-déposé :
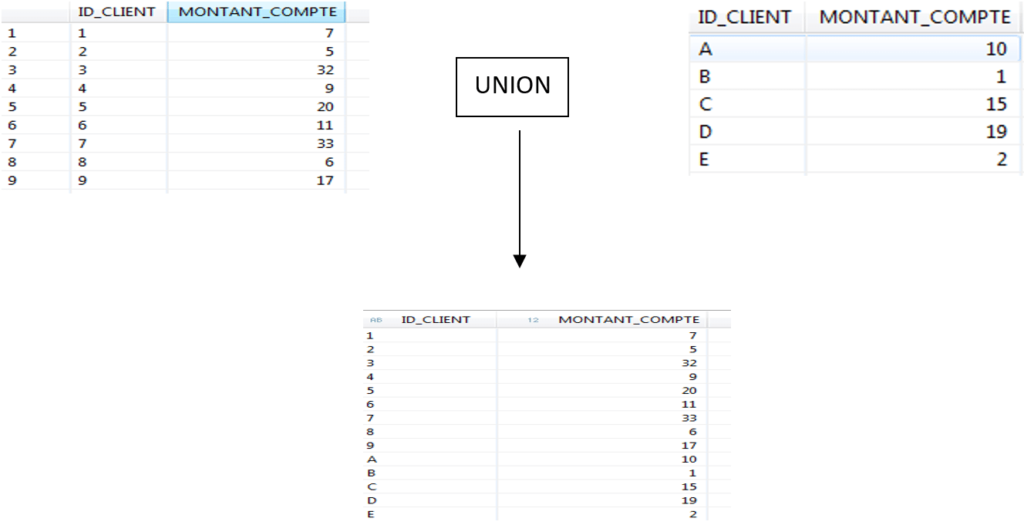
Validez et déployez votre vue, puis faites un « data preview », vous pouvez remarquer que vos deux tables sont fusionnées :
Vue de calcul Standard scriptée
Il existe deux types de vue de calcul utilisant un script SQL.
Script SQL – Utilisation des fonctions CE (Calculation Engine) : Ils sont spécialement optimisés pour HANA et sont exécutés dans le « Calculation Engine ». Ce code est écrit dans HANA Studio sous la perspective « Modeler ».
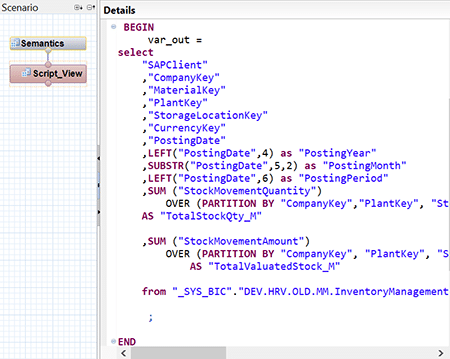
Script SQL – Utilisation des fonctions de table (Table Fonction) : Ce code est écrit dans HANA Studio dans l’onglet « Repositories » sous la perspective « Développement ». Les fonctions de table sont utilisées lorsque les opérations possibles dans les vues graphiques ne sont pas suffisantes.

Moteur d’exécution et optimisation des performances
La plateforme SAP HANA fournit trois moteurs d’exécution qui sont, JOIN Engine, OLAP Engine et Calculation Engine. Un optimiseur de requêtes dans SAP HANA transfère les données à des moteurs distincts en fonction du moteur le plus performant pour la requête.
Lors de la création des vues de calcul, pour obtenir des performances idéales, il faut s’assurer que le bon moteur soit utilisé.
Si la vue de calcul est de type Dimension, le traitement passe au moteur « JOIN Engine », mais s’il y a une colonne calculée, le traitement passe au moteur « Calculation Engine » qui se trouve au-dessus du moteur « JOIN Engine ». De même, si la vue est de type CUBE avec Star Joint, le traitement passe au moteur « OLAP ».
Il est toujours préférable de faire les calculs après l’agrégation (l’agrégation supprime les doublons).
La performance de la vue de calcul augmente considérablement si vous filtrez les données dès que possible en utilisant les paramètres d’entrée, les privilèges analytiques, les agrégations, …
Les jointures doivent être effectuées sur les clés et la cardinalité doit être correctement spécifiée afin d’obtenir les meilleures performances.
CONCLUSION DE L’EXPERT
Les calculation views, dans leur forme graphique, offrent une grande souplesse et permettent de répondre à un grand nombre de problématiques liées à la modélisation. Bien que pour certains besoins précis (jointure de type between, curseur…) leur forme scriptée puisse s’avérer utile (et pratique), on préférera utiliser la forme graphique dans la plupart des cas.
Ouvertes vers la plupart des outils de reporting (SAP BO, PowerBI, Tableau…), les calculations views sont des incontournables dans l’univers SAP HANA.
En respectant les best practice en matière de modélisation, cette technologie vous offrira des performances accrues et simplifiera vos développements.
Enfin, grâce aux privilèges analytiques, vous pouvez ajouter une couche sécurité directement sur vos calculation views, et ce, à un niveau extrêmement fin.



