La concurrence entre les éditeurs d’outils ETL augmente de jours en jours. Cela vient en partie du fait que les entreprises utilisent de nombreux outils et de nombreux progiciels. Ils souhaitent de plus en plus analyser, croiser, fiabiliser et maîtriser leurs données dans un but décisionnel.
De nombreux outils d’extractions, de transformations et de chargements des données existent actuellement sur le marché, ce qui rend le choix difficile.
Qu’est-ce qu’un ETL ?
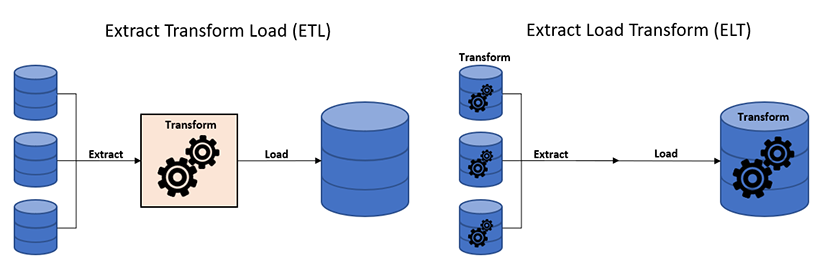
L’abréviation ETL signifie Extract Transform Load (Extraction Transformation Chargement). Il a pour objectif d’uniformiser des données en provenance de différentes sources de données disparates (bases de données, fichiers plats…), de les nettoyer pour ensuite les transformer (agrégations des données par exemple) et enfin de les charger dans une cible (une base de données le plus souvent). On peut ainsi concevoir un DataWarehouse ou mettre en place des interfaces entre les applications.
Dans cet article, nous allons nous intéresser plus particulièrement à l’outil Oracle Data Integrator (ODI).
En l’occurrence, ODI est un Extract Load Transform (ELT), outil d’ETL présentant certaines particularités.
Les objectifs des ELT sont les mêmes que les ETL mais l’approche est différente.
Là où pour les ETL classiques, le moteur propriétaire assure la transformation des données, pour les ELT la transformation est effectuée au niveau des bases de données sources ou cibles.
Quand ce type de besoin émerge au sein d’une entreprise, la première question qui se pose est souvent la suivante : « Quel outil choisir et pourquoi ? »
Pour répondre de manière objective à cette question, il faut prendre en compte un certain nombre de critères même si, quel que soit l’ETL choisi, la finalité reste la même. Ainsi, en fonction de ses besoins et de ses moyens, chacun pourra décider quel ETL ou ELT privilégier.
Oracle Data Integrator
Oracle est un éditeur de logiciels depuis 1977, principalement implanté dans la gestion des bases de données et les progiciels de gestion intégrés. Son ELT, Oracle Data Integrator (ODI), est reconnu pour son architecture flexible et de haute performance.
Ce logiciel permet donc d’extraire des données de sources variables et de les charger dans la cible. La force de cet outil réside dans la transformation des données (filtres, agrégations, jointures, etc.). En effet, cette phase est réalisable en amont (au niveau de la source) ou en aval (au niveau de la cible) en utilisant le moteur SGBDR des technologies déjà en place (source ou cible).
Comme nous le savons, la phase de transformation est la phase la plus exigeante en calcul. De plus, dans le fonctionnement classique des ETL, les données transitent deux fois : une fois de la source vers le moteur ETL et une nouvelle fois du moteur vers la cible.
Cette architecture propose donc une nouvelle solution non centralisée permettant aux utilisateurs de définir le lieu de la transformation.
Oracle Data Integrator permet à ses utilisateurs la création de flux de manière intuitive à l’aide de son interface graphique complète. Un flux représente l’action de transfert et de transformation de données d’une source vers une cible.
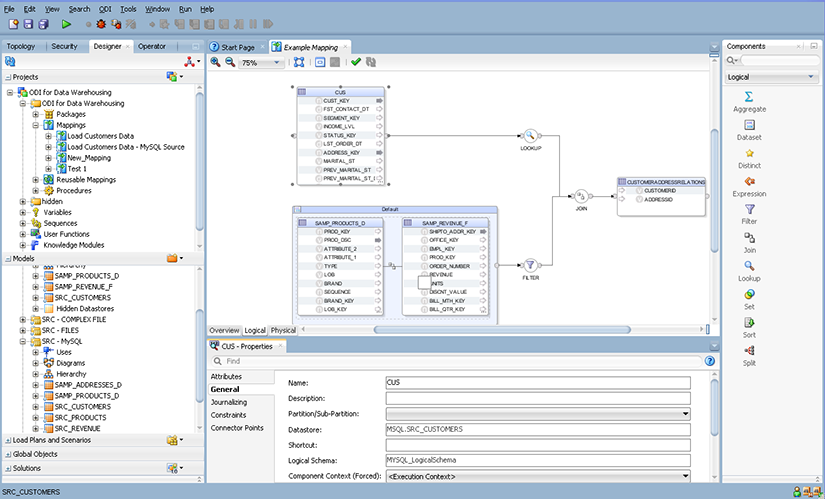
Oracle Data Integrator Studio, les different modules
Les utilisateurs d’ODI (administrateurs et développeurs) travaillent principalement sur Oracle Data Integrator Studio. Le studio propose 4 modules :
- « Designer» : module utilisé par les développeurs pour concevoir les packages, les interfaces (flux) et générer les scénarii.
Un package est un regroupement organisé d’objets (variables, traitements et interfaces) qui a pour objectif de définir l’ordre d’exécution des différents éléments.

Une interface est un flux représentant l’ensemble des étapes de transformation et d’alimentation de la donnée depuis les sources vers la cible. Le développeur choisit le lieu de la transformation de la donnée ainsi que le Knowledge Module (KM) qu’il souhaite appliquer.
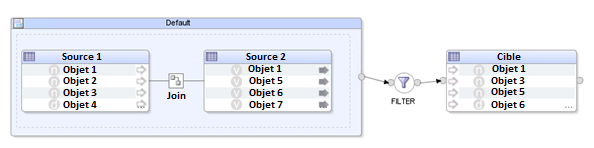
Un Knowledge Module (KM) est une structure de code prédéfinie et modifiable. Dans un KM, on liste et organise l’ensemble des étapes qui seront appliquées lors de l’exécution d’une interface. Le KM va ensuite générer le code approprié pour échanger avec les serveurs de données. Il existe plusieurs types de KM, certains sont notamment dédiés à l’intégration (IKM – Integration), aux chargements (LKM – Load) et aux vérifications (CKM – Check).
Un scénario est un élément généré à partir d’un package. Cet élément est ensuite déployé sur les environnements de production et est utilisé pour l’exécution et l’ordonnancement des développements.
- « Operator» : module utilisé par les développeurs afin de suivre et d’analyser les exécutions.
Dans ce module nous retrouvons l’historique des exécutions réalisées, les exécutions qui ont abouti et celles qui sont tombées en erreur.
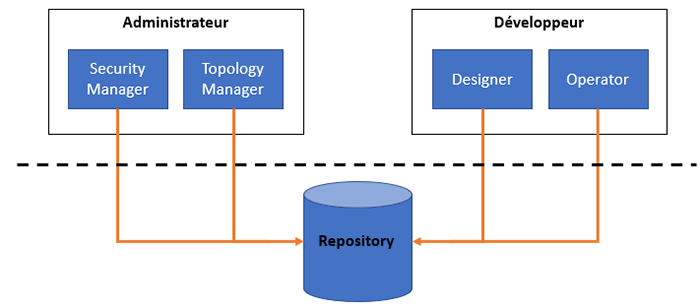
- « Security Manager» : module utilisé par l’administrateur afin de gérer les informations de sécurité (Gestion des utilisateurs, droits d’accès aux objets, droits d’accès aux référentiels.
- « Topology Manager» : module principalement utilisé par l’administrateur décrivant l’architecture physique et logique du système d’information. Ce module permet d’identifier et de gérer les systèmes d’information, les technologies et les serveurs de données (sources et cibles).
Le référentiel (Repository) est l’élément clé de cette architecture. En effet, celui-ci stocke les informations générales (notamment les droits), les projets (packages, scénarii, interfaces, etc.) et les configurations des infrastructures (systèmes d’information). Le référentiel ODI est créé pour permettre l’utilisation de plusieurs environnements séparés (développement, recette, production, etc.) et de faciliter les échanges de métadonnées entre ces différents environnements.
Le repository est ainsi composé d’un référentiel maître qui stocke la sécurité et la topologie (technologies, serveurs de BDD, etc.). Il est également composé d’un référentiel de travail qui, quant à lui, contient les objets propres aux développements.
Les agents sont des composants d’exécution Java qui se connectent aux serveurs de données (source et cible) afin d’y exécuter les scénarii, eux-mêmes récupérés depuis le référentiel. Ils peuvent démarrer l’exécution à la demande ou selon un calendrier prédéfini.
Ces composants orchestrent le processus d’intégration et de transformation en prenant les commandes du code généré et en envoyant ces commandes aux différents serveurs de données.
Oracle Installation ODI 12c
Avant d’installer ODI 12c sur votre poste ou sur un serveur, il vous faut installer Java (JDK). Attention, il faut regarder la version de Java qui sera compatible avec la version d’ODI que vous souhaitez installer.
Vous trouverez ci-dessous les prérequis matériels pour réaliser l’installation d’Oracle Data Integrator :

Points Forts de Oracle Data Integrator
- Grande performance liée à l’architecture (ODI échange avec les systèmes sources et cibles en utilisant leur langage).
- Facile à mettre en place (pas de système intermédiaire à installer).
- Les données transitent une fois, directement entre les sources et la cible.
- Utilisation des technologies déjà en place (sources et cibles) pour réaliser la transformation.
- Le designer propose des interfaces graphiques intuitives facilitant la compréhension des flux, la maintenance et le débogage.
- Un simple export/import des scénarii suffit pour le déploiement sur les environnements cibles (ex : mise en production).
- Possibilité de créer et de modifier les Knowledge Management (KM).
- Disponibilité et documentation de l’éditeur.
Points Faibles de Oracle Data Integrator
- Outil d’ETL payant avec des licences coûteuses.
- Ne propose pas de version de test.
- L’outil est très complet (4 modules) ce qui rend l’appropriation et la prise en main plus difficiles.
- L’utilisateur doit agir dans l’objectif de centraliser les transformations au même endroit (l’unicité et la cohérence du système d’information en sont les enjeux).
- Manque de soutien communautaire comparé aux autres ETL.
CONCLUSION DE L’EXPERT
Tout d’abord, il est important de choisir l’outil d’intégration des données qui correspond le plus à vos besoins et à vos moyens et qui peut être mis en œuvre avec les ressources et les compétences dont vous disposez.
Comme vous l’avez compris, ODI se démarque des autres ETL par son architecture atypique. Celle-ci lui permet d’assurer de bonnes performances et lui confère une réelle robustesse.
Au vu du prix et du temps nécessaire à la prise en main, il n’est pas recommandé de choisir ODI pour des petites tâches ou des projets spécifiques. L’outil montrera davantage son plein potentiel dans le cadre d’un gros projet ETL.
Vous pourrez alors identifier vos technologies (serveurs de base de données) et utiliser leurs performances dans l’ensemble du processus ETL.




