Introduction
En septembre dernier, Stambia a communiqué officiellement quant à sa fusion avec Semarchy, éditeur français de solutions logicielles et spécialiste du data management et de la gouvernance de la donnée. Il a été fait part, dans le cadre de cette annonce, que l’outil Stambia DI porterait dorénavant la dénomination de Semarchy xDM Data Integration.

Grâce à cette démarche, les utilisateurs pourront bénéficier d’une plateforme plus complète, en ce sens qu’il leur sera possible de mettre en place une plateforme unifiée de la donnée à travers les produits de Semarchy, en addition aux fonctionnalités déjà connues de Stambia.
Il convient de préciser que ce changement n’a pas de répercussions majeures sur la suite Stambia DI (Designer, Runtimes, Analytics). En effet, l’architecture technique ainsi que les interfaces demeurent les mêmes.
Dans cet article, nous allons nous intéresser de plus près au Designer et en voir différents concepts et notions.
Vue d’ensemble
Designer est une interface graphique (basée sur Eclipse) qui permet de créer les flux d’intégration des données, en y appliquant les transformations nécessaires pour répondre aux besoins fonctionnels de l’organisation.
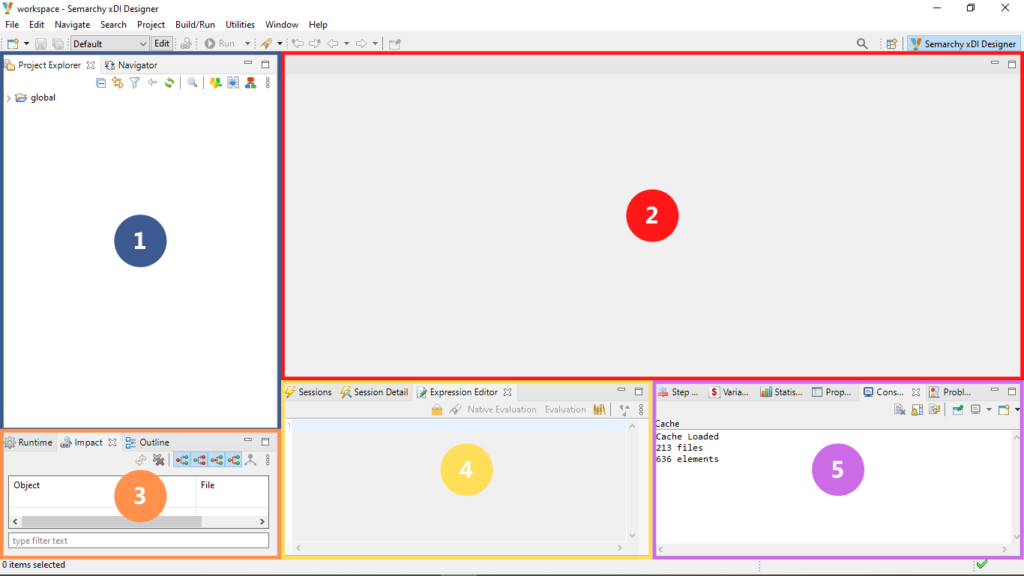
Sur le compartiment (1), l’intégralité des objets créés/importés seront affichés. Il peut s’agir de projets, métadonnées, mappings, etc.
Dans la fenêtre (2), nous allons pouvoir concevoir les mappings (flux) en définissant les sources et cibles à partir des métadonnées précédemment créées et en opérant les transformations grâce à des formules SQL. Celles-ci sont à renseigner dans l’éditeur de formules se trouvant sur la zone (4).
Dans la zone (3), il est possible de se connecter aux différents environnements existants, et de réaliser une analyse d’impact.
Enfin, sur la zone (5), nous avons accès à d’autres informations tels les détails et les statistiques d’exécution des flux, les valeurs prises par les variables, les propriétés des mappings, etc.
Métadonnées
Rappelons qu’une métadonnée est une donnée « sur la donnée ». En d’autres termes, il s’agit ici de données supra, servant à décrire le schéma des objets auxquels nous devrons faire appel.
Ce concept est au cœur de tout développement sur Semarchy. En effet, l’intégralité des sources et cibles seront définies par leurs métadonnées. Cela passe par le processus de reverse engineering.
Dans l’exemple ci-dessous, nous souhaitons récupérer le schéma d’un fichier plat :
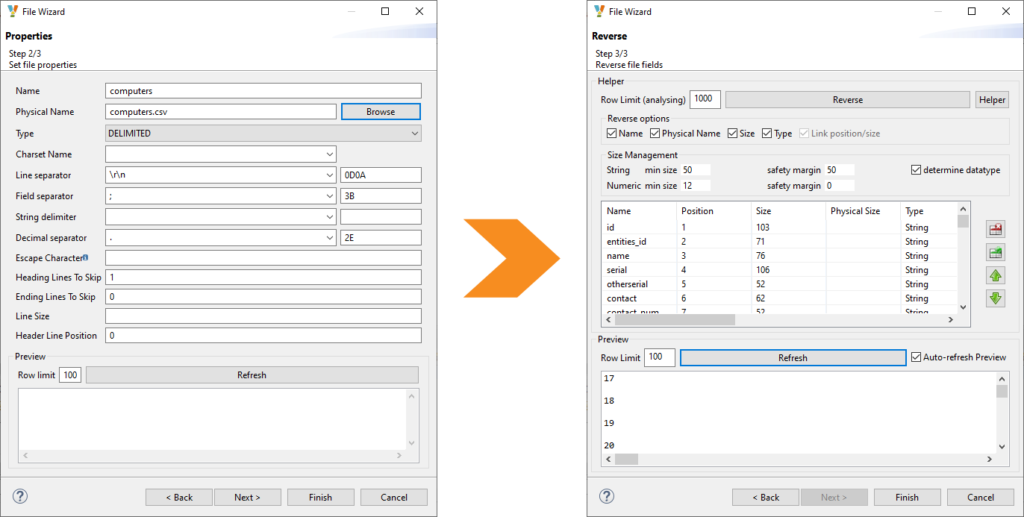
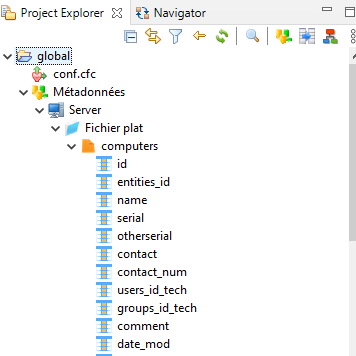
Une fois les propriétés définies et vérifiées, nous retrouvons la structure du fichier dans l’explorateur de projet.
Voici une liste non exhaustive des technologies à partir desquelles il est possible de créer des métadonnées, et par extension, extraire des données :
- base de données : Cassandra, Elasticsearch, Firebird, Hive, IBM DB2, Impala, Informix, Oracle, PostgreSQL, Microsoft Access, Microsoft SQL Server (MSSQL), MariaDB, MongoDB, MySQL, Netezza, Vertica, SAP Hana, Teradata, Actian Vector, Sybase IQ, …
- Cloud : Amazon Web Service (AWS), Google Cloud Platform (GCP), Microsoft Azure, Snowflake, …
- Application ERP/SaaS : SAP, Microsoft Dynamics, Salesforce, Snowflake, Big Query, SpreadShit
- Systèmes distributés : Spark, Hadoop
- Fichiers ; CSV, XML, JSON, Excel …
Pour connaître tous les connecteurs disponibles sur Semarchy, il est possible de consulter la page prévue à cet effet sur le site officiel de l’éditeur : https://www.semarchy.com/doc/semarchy-xdi/xdi/5.3/Components/overview.html
Composants dans un mapping
Contrairement à d’autres outils de marché, Semarchy offre la possibilité de développer des mappings complexes grâce à deux composants seulement : jointures (entre différentes sources) et filtres. Toute autre transformation se fera directement au niveau du champ cible, via une syntaxe SQL qui sera saisie dans l’éditeur de formule, ou une fonction personnalisée créée par l’utilisateur éventuellement.
Voici un exemple de mapping conçu sur Semarchy, dans lequel 4 tables sources sont reliées les unes aux autres et alimentent toutes la même cible :
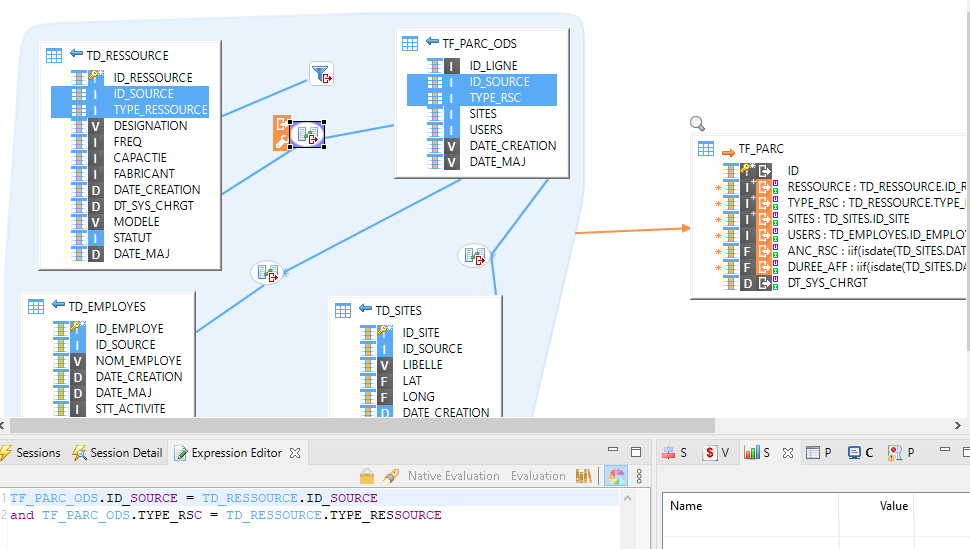
Par ailleurs, il demeure possible d’introduire une étape intermédiaire sous forme de table, vue ou encore de sous requête. De même, l’utilisateur peut spécifier un paramétrage avancé de l’exécution du flux (option commit, vider la cible avant chargement, timeout…).
Editeur SQL
Semarchy est doté d’un éditeur SQL qui permet d’exécuter des requêtes sur les objets dont les métadonnées sont référencées. En plus de pouvoir afficher les données, il est possible d’exécuter tout type d’instructions sur cet éditeur (Alter, Upddate, Truncate, Delete, etc.) ce qui évite d’avoir recours au SGBD. Une requête saisie sur l’éditeur peut faire l’objet d’une sauvegarde sous forme d’un script SQL.
Le résultat de l’exécution pourra être visualisé sur la partie basse de la fenêtre de l’éditeur. En cas d’erreur, le message et le code correspondant sont retournés.
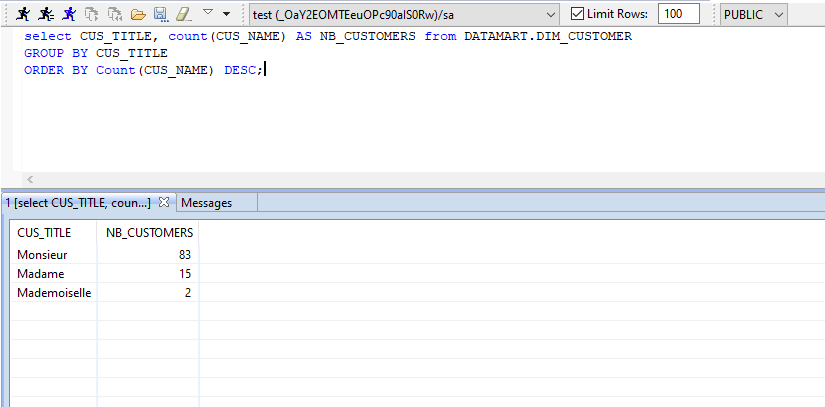
Dans l’exemple ci-dessus, nous avons calculé le nombre de clients recensés par civilité sans affecter la table d’origine.
CONCLUSION DE L’EXPERT
Bien que Stambia et Semarchy aient fusionné, la suite Data Integration offre toujours les mêmes fonctionnalités qu’auparavant puisque les outils Designer, Analytics et Runtime n’ont pas connu de changements.
Dans ce sens, la vision initialement proposée par Stambia en termes d’agilité dans le développement des flux de données est toujours d’actualité. Cela se traduit en pratique par la conception même du Designer et la praticité quasi inégalable qu’offre ce dernier aux développeurs en leur permettant de s’affranchir de la complexité technique habituellement connue des outils ETL. En effet, avec peu de composants, les développeurs peuvent parfaitement concevoir des flux complexes tout en se focalisant sur l’aspect fonctionnel de la donnée et garantir la fiabilité de cette dernière.
En définitive, la solution Semarchy est un outil performant et innovant qui se démarque par la facilité de son déploiement, sa prise en main et la simplicité des développements.




