Introduction
Sortie en 2018, Azure Data Factory V2 est le nouveau service de traitement de la donnée de Microsoft. Tout comme son grand frère SSIS, l’outil permet la création et la gestion de projets d’Extraction, de Transformation et de Chargement (ETL) mais également l’Extraction, le Chargement puis la Transformation (ELT), le tout hébergé dans le cloud Azure. Le service utilise le langage JSON.

Note : l’onglet release très utile, vous permet de consulter les dernières évolutions livrées. Le service est en amélioration continue.
Composants de Azure Data Factory
Edition
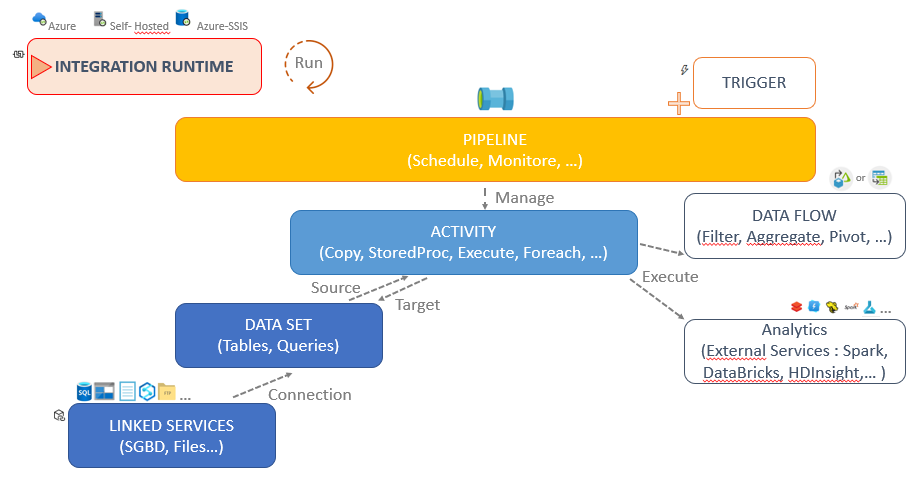
L’intégration runtime est le moteur de calcul de Azure Data Factory, il est chargé des tâches suivantes :
- Exécuter les Data Flow avec un moteur Spark managé Azure.
- Intégrer les données, les connecteurs intégrés, la conversion de format, le mapping des colonnes, ainsi que l’optimisation du transfert de données.
- Répartir les activités de transformation exécutées sur un large éventail de services de calcul externes ou intégrés.
- Exécuter des packages SSIS avec un moteur managé Azure.
Avec ce service, vous disposez d’interface « user-friendly » pour faciliter l’intégration de vos données.
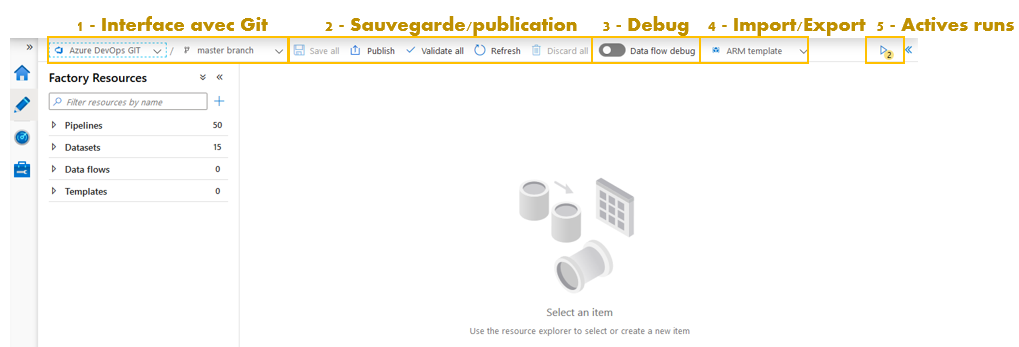
1 – Il est conseillé d’interfacer Azure Data Factory avec Git à l’aide d’une souscription Azure DevOps. Git garantit le versionning, les développements parallèles avec gestion des conflits à travers des branches. Chaque développeur peut développer localement de nouveaux contenus dans une branche locale et ensuite les réconcilier dans la branche principale.
2 – Lorsqu’un développement doit être planifier ou mis en production il est nécessaire de publier le code. Le code JSON est alors compiler pour produire un fichier ARM utilisé pour les déploiements d‘environnement.
3 – Le mode DataFlow Debug lance un Intégration runtime nécessaire pour tester et exécuter les transformations d’un DataFlow. Une session DataFlow nécessite un temps d’initialisation et dure généralement 60min sans activité. Chaque heure mémoire utilisée est facturée en fonction du paramétrage de l’intégration runtime.
4 – Il est possible d’importer ou exporter le fichier ARM comprenant l’ensemble du contenu de l’instance Azure DataFactory. C’est très utile pour réaliser des déploiements manuels. Il est également possible d’automatiser le déploiement entre différentes instances à l’aide Azure DevOps Pipeline ( / !\ différent des pipelines DataFactory).
5 –Accès à la liste des sessions pipeline ou dataflow en cours de debug.
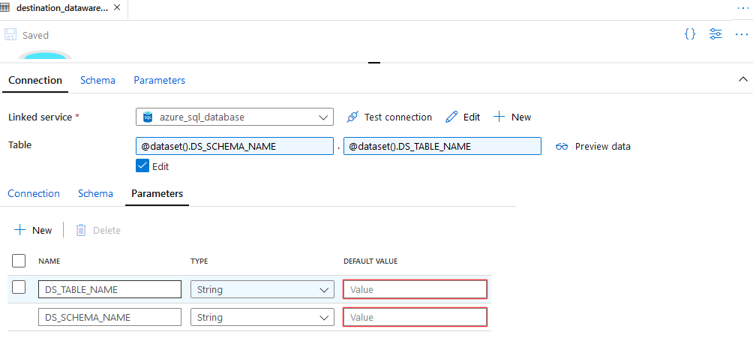
La donnée est intégrée dans des magasins de données, Data Set, ils servent de source et/ou de cible pour les activités. Un Data Set correspond à l’appel d’un linked service qui contient la chaine de connexion des systèmes opérationnels sources et des systèmes décisionnels ou analytics cibles.
Pour simplifier l’utilisation et la quantité des DataSet il est préférable d’ajouter des paramètres (ex : schema/table) pour les rendre génériques et laisser le Pipeline se charger des valeurs.
Le chargement de la donnée et l’orchestration des flux est réalisé avec les pipelines. Un flux est composé d’activités, liées en séquentielles ou en parallèles, qui s’enchainent en fonction du statut de l’exécution (Success, Failure, Completion, Skipped). La généricité des pipelines est possible avec :
- les paramètres, partagés avec les Datasets et Linked Services, qui conditionnent le lancement
- les variables, internes aux pipelines, pour passer des valeurs entre activités.
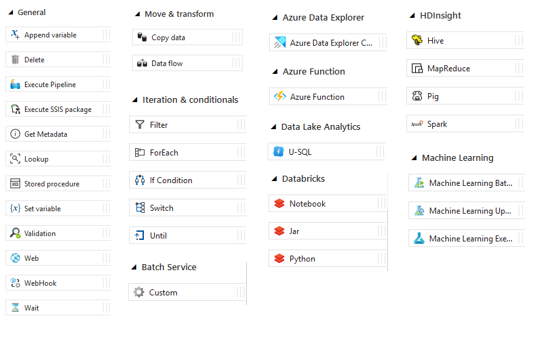
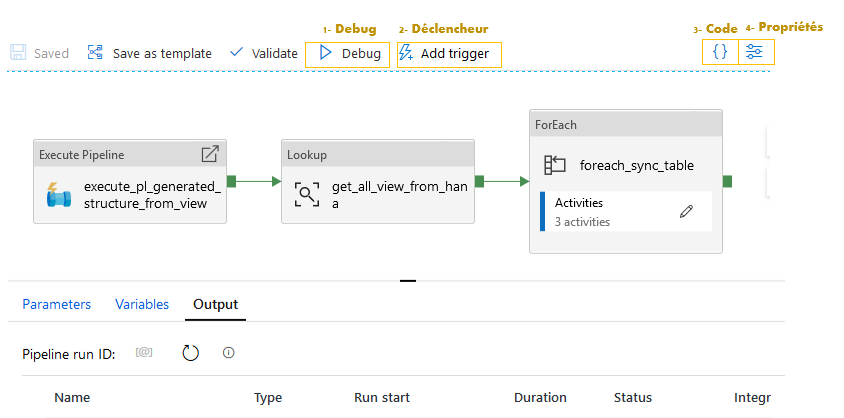
1 – Le mode Debug lance le pipeline en direct. Les logs du pipeline sont restitués dans l’onglet Output. Ils sont conservés seulement le temps de la session.
2- Add triggers facilite la création d’un déclencheur sur le pipeline, soit un trigger unique (Now) immédiat, soit un trigger planifié (New/Edit). Les logs du pipeline sont restitués dans le monitoring et sont conservés. Attention il faut publier le code du pipeline et du trigger associé pour qu’il se lance en monitoring.
Les transformations sont pilotées depuis les pipelines à travers les activités.
Elles peuvent exécuter des scripts sur des services externes en intégration ELT. Ces services comme HDInsight Hadoop, Spark, Data Lake Analytics et Machine Learning, SQL vont hébergés les transformations en langage SQL, Python, Scala, R, SQL Spark…
Les activités Data Flow peuvent directement transformer de la donnée en mode ETL. Deux interfaces distinctes offrent un confort de développement sur un moteur Spark auto-géré avec du code auto-généré.
- Data Flow Mapping : développement sous formes de graphes avec une possibilité de surcouche en Format Parquet ou en JSON.
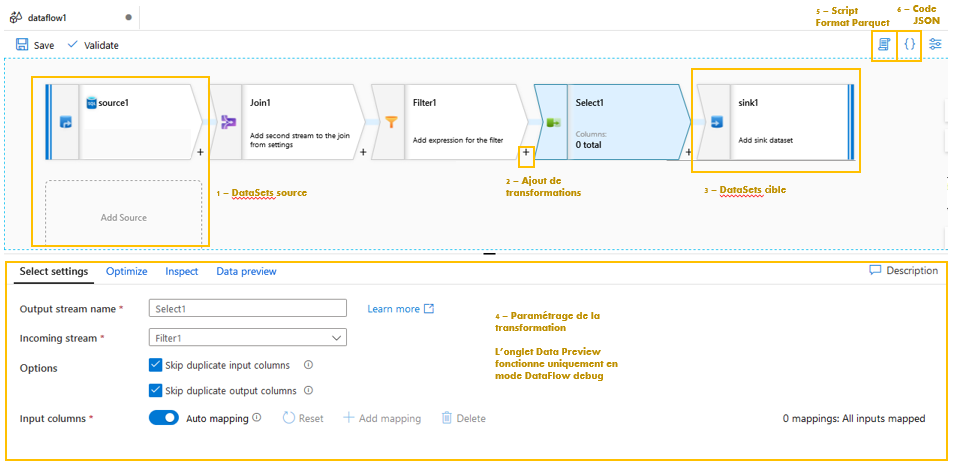

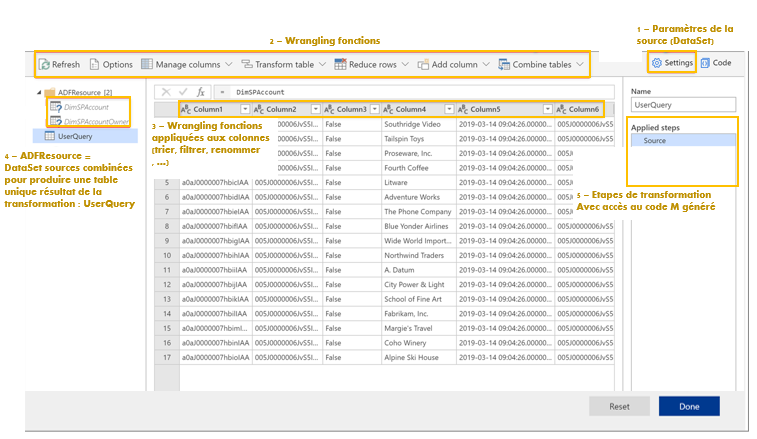
- DataFlow Wrangling : développement sous interface Power Query (comme Power BI) avec une possibilité de surcouche en M ou en JSON.
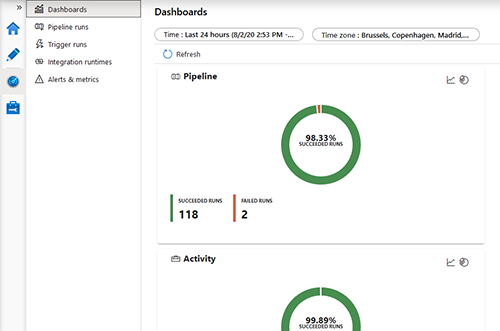
Monitoring
Enfin une interface de monitoring permet de superviser, gérer, planifier et déclencher tous vos traitements. Le monitoring est uniquement en mesure d’exécuter des triggers contenant du code JSON publié en ARM.
Avantages de Azure Data Factory
- Service PaaS qui garantit un confort d’architecture et de maintenance.
- Interface user-friendly pour développer rapidement des flux simples.
- Service d’intégration de données complet : ETL/ELT, ordonnanceur et monitoring
- Interface possible avec Azure DevOps (Git) pour fiabiliser les développements et les déploiements
- Comptabilité possible pour lancer les packages SSIS existants et éviter une double gestion d’infrastructure.
Inconvénients de Azure Data factory
- Souscription Azure indispensable avec parfois une maîtrise des coûts difficiles à évaluer au démarrage. Tarification : https://azure.microsoft.com/fr-fr/pricing/details/data-factory/
- Une routine de développement est à acquérir pour stopper les services et éviter des coûts inutiles.
- Pour réaliser des flux complexes, la connaissance des langages utilisés est un plus pour surcharger le code lorsque l’interface est incomplète.
- L’outil est toujours en évolution. Certaines fonctionnalités sont en Preview et contiennent encore des bugs.
- Limites officielles : https://github.com/MicrosoftDocs/azure-docs/blob/master/includes/azure-data-factory-limits.md
CONCLUSION DE L’EXPERT
Azure Data Factory demande un changement de paradigme pour le développeur. On ne travaille plus avec un outil mais un service.
Il faut donc garder à l’esprit que la licence à un coût à l’utilisation pour ne pas voir la facture grimper rapidement.
Le service est continuellement en évolution. Il faut consulter régulièrement les releases car il n’y a plus de cycle de montée de version qui déclenchait des sessions de montée en compétences et de refactoring.
L’effort de veille technologique devient continu et lissé dans le temps.
Encore jeune, ce service manque parfois de fonctionnalités et de retours d’expérience mais la documentation Microsoft est très fournie et la prise en main rapide.
Pour conclure si le SI effectue un virage dans un environnement Microsoft Azure ce service est le plus adapté. Dans une architecture plus classique, il reste le gap du cloud à franchir pour bénéficier des atouts de ce service.



