Introduction
Aujourd’hui, les entreprises n’ont jamais eu autant de données à leur disposition. Pourtant, transformer ces données en information utile reste un véritable défi. Entre-les datalakes, les data Warehouse, les pipelines ETL et les outils d’analyse, les environnements de données sont souvent complexes, coûteux et difficiles à faire évoluer.
C’est pour répondre à ces problématiques que Databricks a vu le jour. Pensée pour le cloud et construite sur Apache Spark, cette plateforme vise à réunir les mondes du data engineering, de la data science et de l’analyse au sein d’un même espace de travail collaboratif. Grâce à son approche dite du Lakehouse, Databricks permet de traiter, stocker et exploiter les données de manière unifiée, tout en facilitant les projets d’intelligence artificielle et de machine learning.
Dans les lignes qui suivent, je vous propose de découvrir ce qu’est Databricks, comment il fonctionne et comment il permet l’ingestion et la transformation de données.
Qu’est-ce que Databricks ?
Databricks est une plateforme cloud unifiée d’analyse de données et d’ingénierie qui permet de préparr, analyser et exploiter les données à grande échelle.
Il combine plusieurs usages :
- Ingestion et transformation de données (ETL/ELT)
- Analyse exploratoire et date science
- Machine Learning
- BI (via intégration Power BI, Tableau, etc.)
Databricks repose sur trois grands piliers à savoir :
- Databricks Workspace qui est l’environnement de travail collaboratif
- Databricks Runtime qui est le moteur d’exécution optimisé
- Databricks Lakehouse Platform qui combine les avantages d’un Data Lake et d’un Data Warehouse
Inscrivez-vous à la newsletter DeciVision !
Soyez notifiés de nos derniers articles de blog, de nos prochains webinars et nos actualités !
Comment fonctionne Databricks ?
Databricks n’est pas un logiciel à installer localement. C’est une plateforme managée hébergée sur les principaux cloud (Azure, AWS, Google Cloud). Il permet de créer en quelques minutes des environnements de travail collaboratifs, appelés Workspace, où les équipes data peuvent écrire du code, exécuter des traitements et visualiser les résultats.
Pour travailler sur Databricks, il faut créer un Cluster.
Au cœur du fonctionnement de Databricks se trouve le cluster : un ensemble de machines virtuelles (nodes) qui exécute les calculs via Apache Spark. Lorsqu’un utilisateur lance un notebook ou un job, le cluster distribue automatiquement les calculs sur plusieurs machines pour accélérer le traitement des gros volumes de données.
Databricks fonctionne comme une plateforme cloud tout-en-un qui combine puissance de calcul, fiabilité du stockage et collaboration entre équipes data. Le tout repose sur Apache Spark et Delta Lake, deux technologies qui garantissent performance et scalabilité.
Cas pratique : Ingestion et transformation de données
L’un des usages les plus courants de Databricks concerne l’ingestion et la transformation de données à grande échelle. Avant d’être analysées ou utilisées dans un tableau de bord, les données doivent souvent passer par plusieurs étapes : nettoyage, harmonisation, enrichissement, puis stockage dans un format exploitable. C’est précisément sur ce terrain que Databricks excelle.
Grâce à son moteur Apache Spark et à son format Delta Lake, la plateforme permet de créer des pipelines de données performants, fiables et faciles à maintenir. Les équipes peuvent se connecter à de multiples sources (fichiers plats, bases de données, API, stockage cloud…) et centraliser le tout dans un Data Lakehouse.
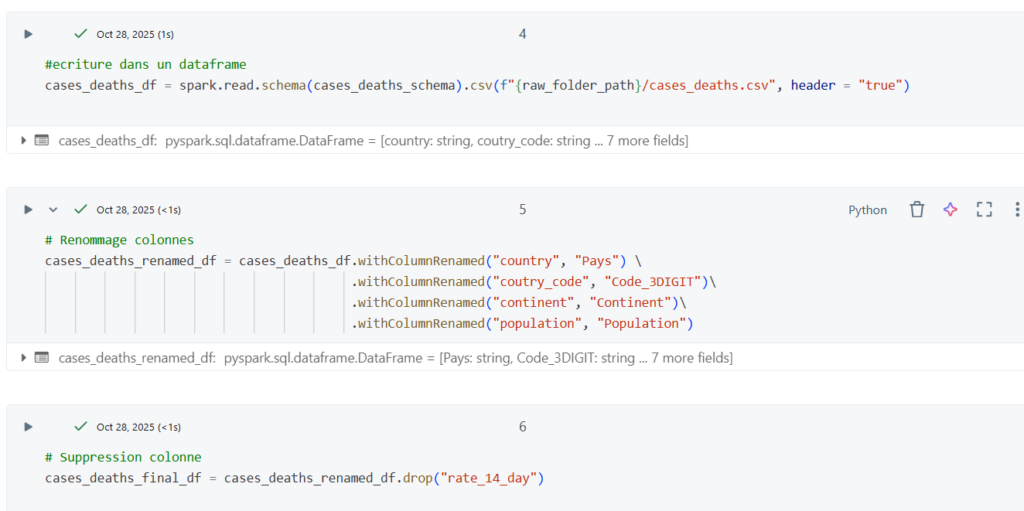
Une fois les données ingérées, les notebooks Databricks (en Python, SQL ou Scala) offrent une grande flexibilité pour les transformer :
- Nettoyage et suppression de valeurs inutiles
- Jointure en plusieurs jeux de données
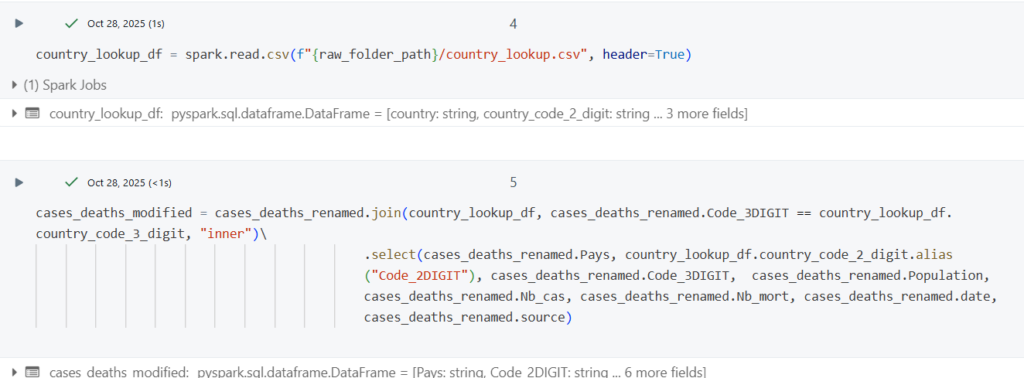
- Calcul de nouveaux indicateurs ou agrégations
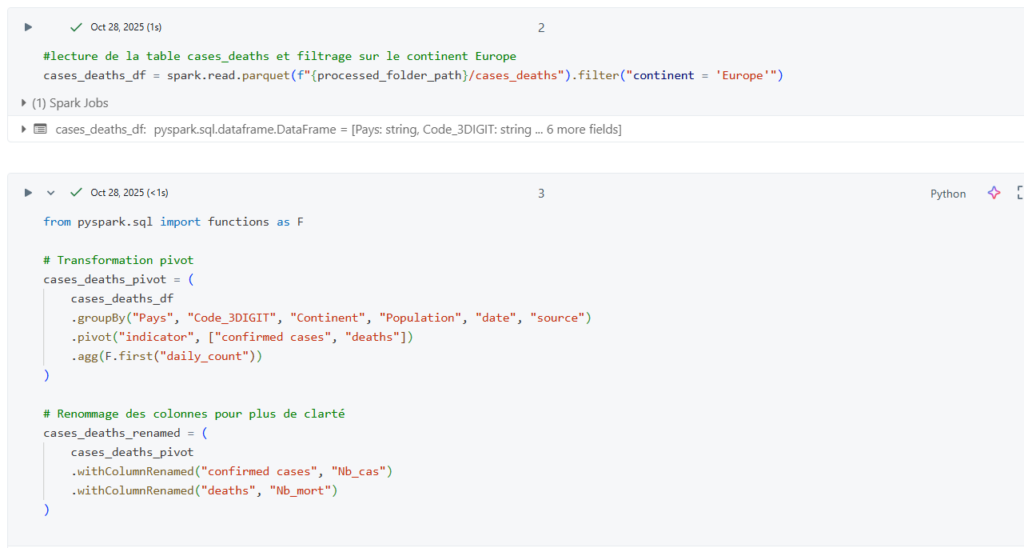
- Écriture des résultats en Delta Lake, assurant la gestion des transactions ACID et la traçabilité des modifications

L’avantage clé réside dans la scalabilité automatique : que vous traitiez quelques milliers de lignes ou plusieurs téraoctets, le cluster Spark s’adapte à la charge. Les pipelines peuvent ensuite être automatisés via les jobs Databricks ou orchestrés depuis un outil externe comme Azure Data Factory.
En combinant puissance, flexibilité et fiabilité, Databricks simplifie ainsi tout le cycle de vie des données, de leur arrivée brute jusqu’à leur mise à disposition pour l’analyse ou la visualisation.
CONCLUSION DE L’EXPERT
Databricks s’impose aujourd’hui comme une solution incontournable pour les entreprises souhaitant moderniser leur gestion et leur exploitation des données. En unifiant les mondes du data engineering, de la data science et de l’Analytics au sein d’une même plateforme cloud, elle simplifie considérablement les processus d’ingestion, de transformation et d’analyse.
Grâce à l’architecture Lakehouse et à la puissance d’Apache Spark, Databricks offre un environnement à la fois flexible, performant et évolutif, capable de traiter des volumes massifs de données tout en garantissant la fiabilité et la traçabilité nécessaires aux projets critiques.




